当企业级 Agent 步入生产环境,懂语义却查不对业务事实成了落地的最大痛点。为了拼凑完整的上下文,许多团队被迫进行多库拼接,导致推理链路极度割裂。既然纯向量检索撑不起复杂的混合查询,Agent 真正缺失的底层数据入口究竟在哪里?
过去几十年,数据分析一直是企业数据基础设施最重要的舞台,无论是经营看板、实时报表、用户行为分析、风险监控,还是临时钻取和复杂查询,本质上都在解决同一个问题:如何将业务数据转化为人类可理解的事实。
当 Agent 进入生产系统后,这一层的价值非但没有被削弱,反而成为了战略刚需。Agent 在执行任务时,首要诉求不是模糊的语义,而是订单、用户、交易、库存、告警等明确的业务事实。换言之,Agent 的诸多核心任务,底色依然是分析任务。
于是,实时、低延迟、高并发、统一查询这些实时分析系统的能力,开始变成 Agent 时代的准入门槛。我们可以通过一张对照表,直观感受这种变化:
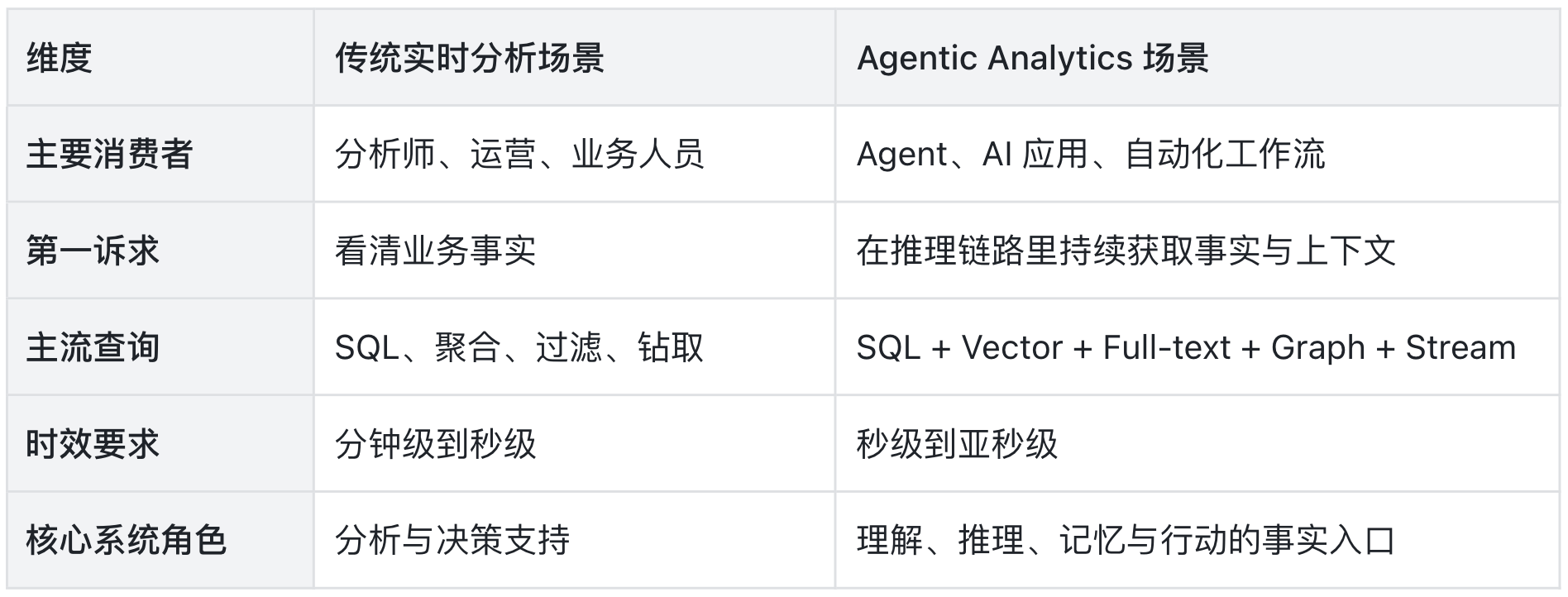
顺着这个脉络,就能清晰感知:为何多模数据管理会成为核心能力,以及 Apache Doris、SelectDB 这类系统为何能在新一轮演进中占据关键身位。
纯语义不是企业级 Agent 的第一入口
提及 Agent,人们往往先想到向量数据库、RAG 或工作流编排。但放到真实企业场景里,Agent 接手的任务毫不抽象。
比如:客服 Agent 要先了解订单、物流与退款状态;经营分析 Agent 必须掌握收入、转化率与异常波动;运维 Agent 得先摸清告警范围与资源使用率。这些均非纯语义检索,而是典型的实时分析问题 。
如果还不够直观,我们将核心场景中 Agent 依赖的能力进行具象化拆解:
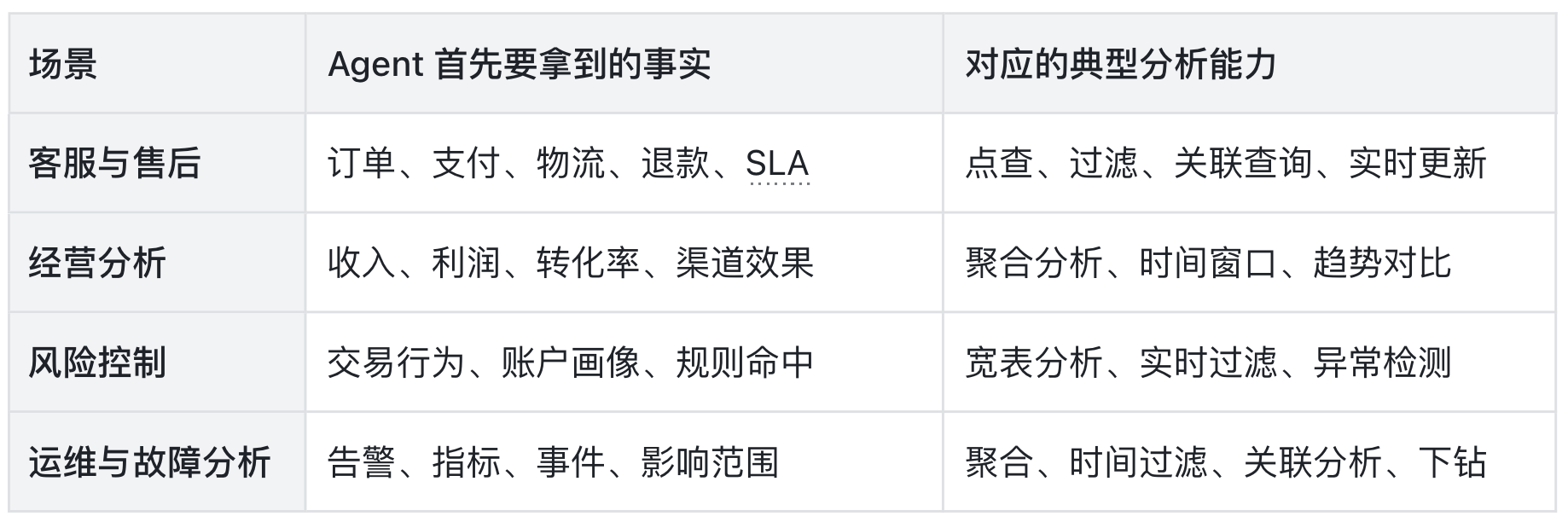
由此可见,Agent 时代的数据入口,是从实时事实查询开始。
多模的本质:让分析引擎进化为统一上下文层
多模数据常被“误解”为一个与传统分析系统平行、甚至相互替代的新事物,仿佛只要涉及图片、音视频、向量和知识图谱,问题就自然而然从 OLAP 跳到了另一个多模体系里。
实际上,多模的真正价值是让分析系统无限贴近真实业务。对于 Agent 来说,结构化事实仍然是骨架,多模态信息是把这层骨架补全为可以理解、可以解释、可以行动的上下文系统。
例如,一个运维 Agent 不只要知道收入受损是否超过阈值(事实),还需要关联故障日志、历史相似事件和应急手册(解释)。
因此,多模融合不仅是支持更多数据类型,更是把事实、解释、行为、记忆和语义,统一编排为一个 AI 可以稳定消费的 Context Layer(上下文层)。
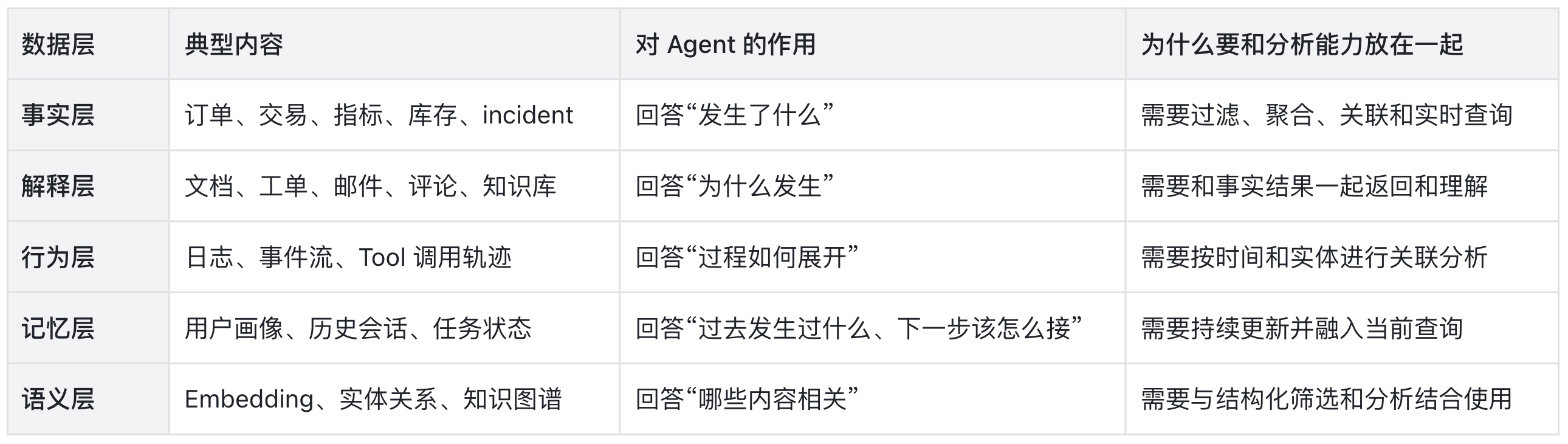
在这个维度上,多模态不仅没有脱离 OLAP,反而促使实时分析引擎从单一的分析系统(Analysis System),进化为全局统一的上下文系统(Context System)。
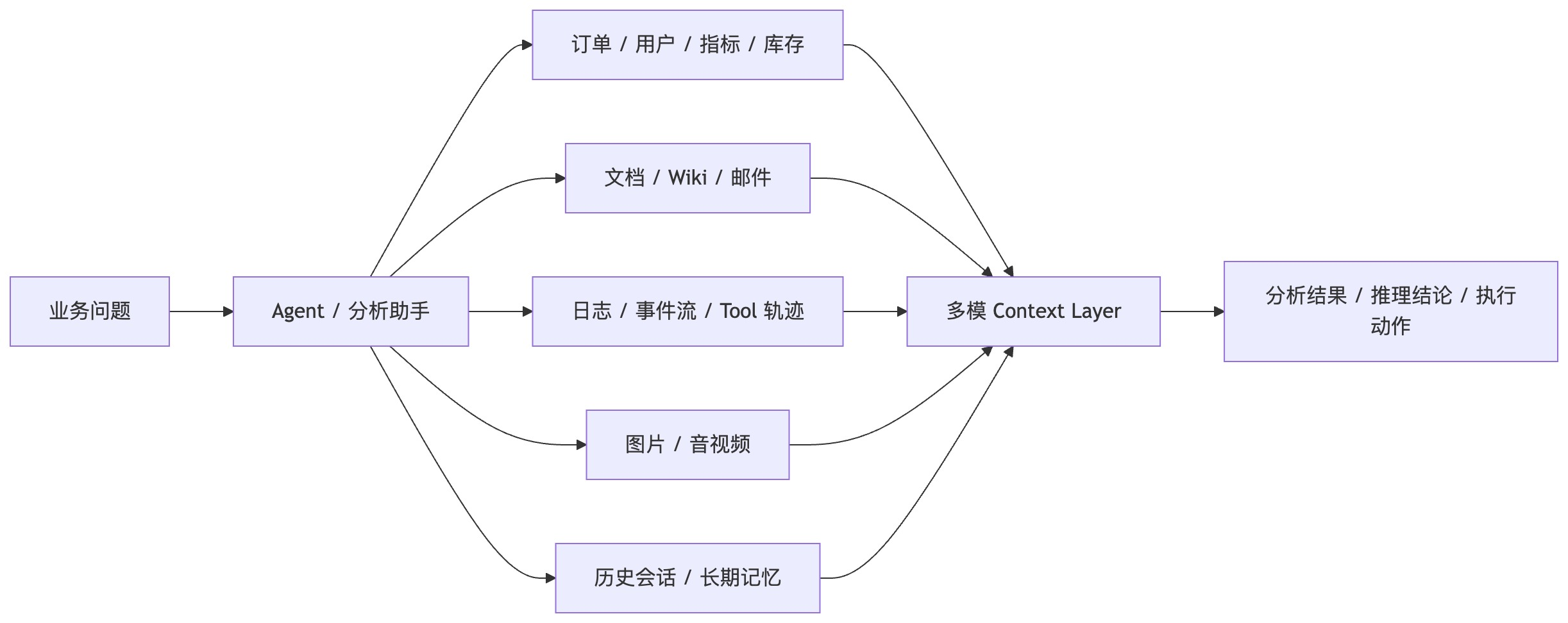
多数据库拼接在 Agent 场景下失效
审视当下的企业技术栈,大多是按能力拼接的。在传统系统里,人类大脑隐式补全了各组件间的缝隙,系统尚能运转。但在 AI Agent 面前,情况发生了本质变化。
Agent 真正需要的是一条尽可能短的数据链路。一旦单次任务被迫在多套底层系统间反复跳转,很多隐患就会集中爆发:
- 上下文(Context)分裂。 数据虽然都在,但 Agent 看到的往往只是碎片,而不是完整事实
- 一致性问题。多个系统的同步频率、索引刷新和权限模型不同,任何一处错位,都会直接影响 Agent 的判断质量。
- 成本与延迟失控。 单次查询演变成多次网络调用与多轮结果整合,导致推理链路变慢甚至崩溃。
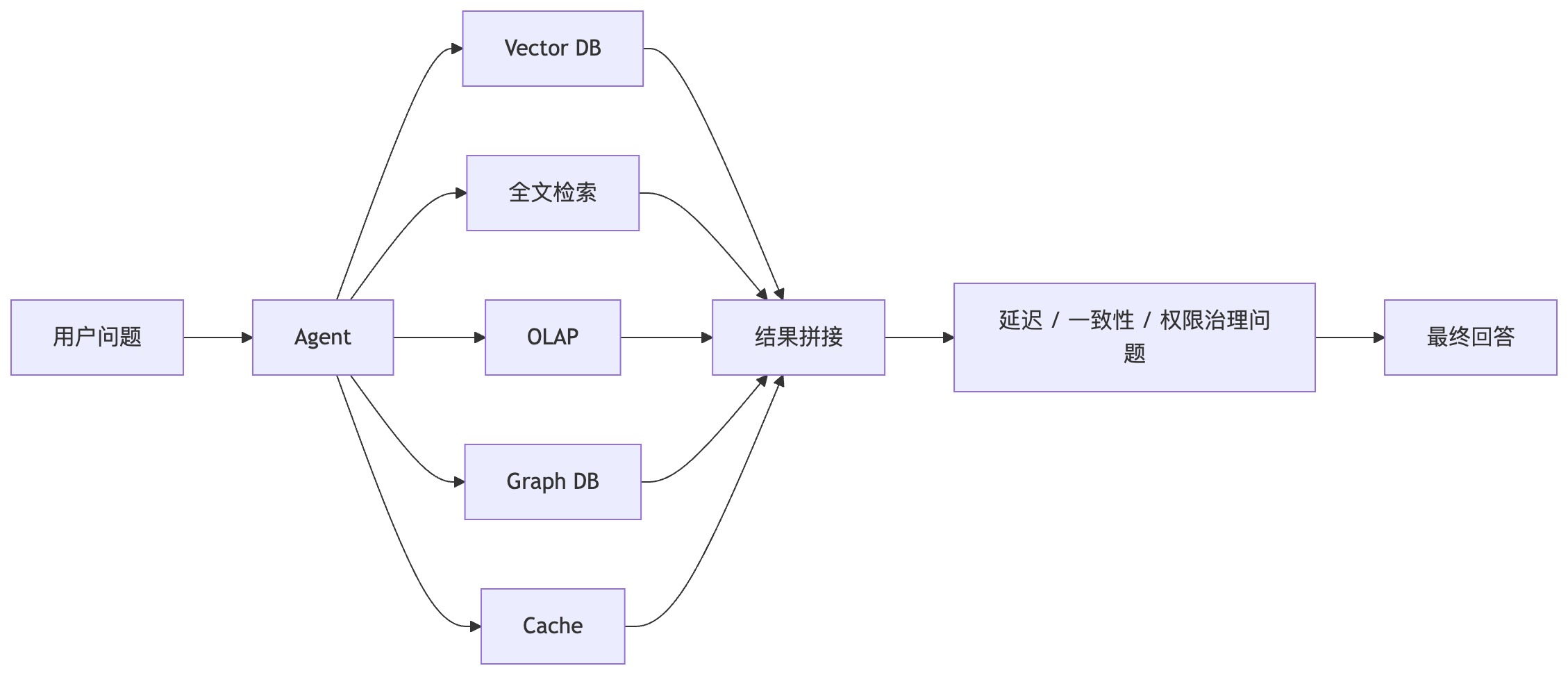
正因如此,当一套实时分析系统能够向内吸收全文检索、向量检索以及半结构化数据处理能力时,原本散落的复杂组件,就被成功收拢为一条更短、更稳、更高效的 Agent 核心数据路径。
Agent 需要基于实时分析的 Hybrid Search
很多 RAG 系统把重点放在向量检索上,但真实的业务查询天然是混合的(Hybrid Query)。
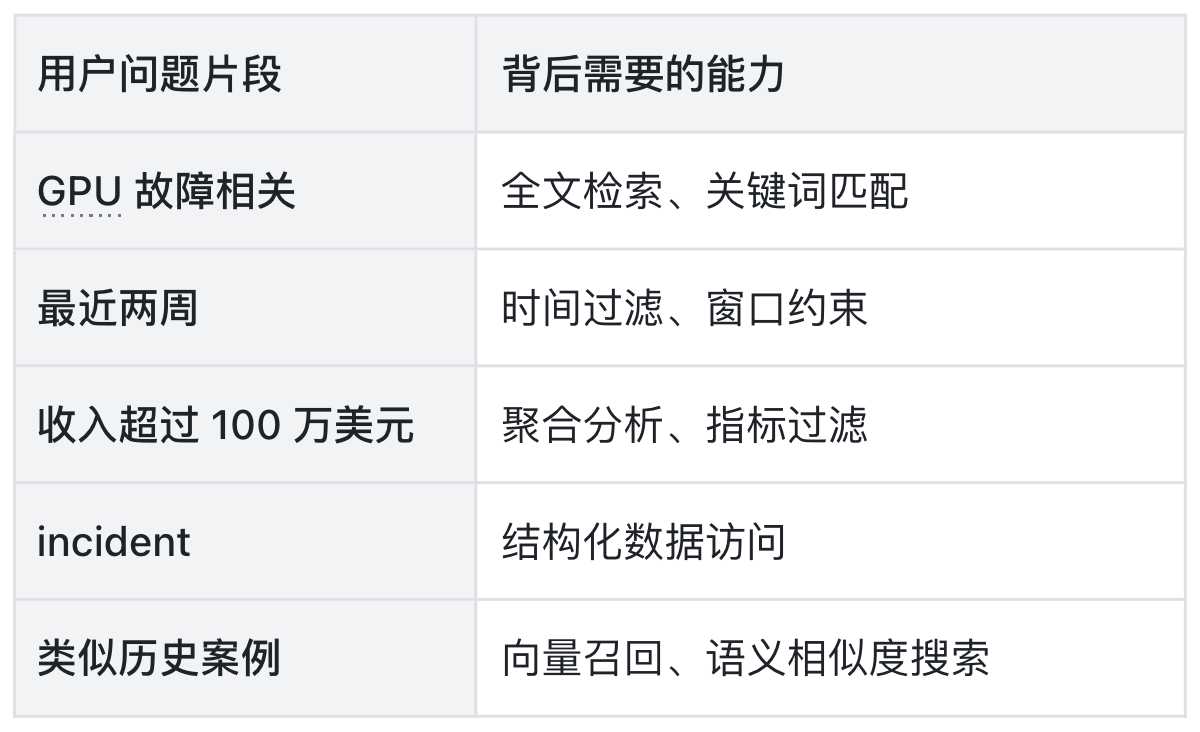
比如,当用户向 Agent 提出:“找出最近两周内,因 GPU 故障引起,且导致收入损失超过 100 万美元的相关 incident,并附带相似的历史案例。”
我们将其进行能力拆解:
在未来的 Agent 交互中,底层生成的典型查询可能长这样:
SELECT *
FROM incidents
WHERE l2_distance(description_embedding, query_embedding) < 0.1
AND MATCH(log_text, 'GPU overheating')
AND severity >= 4
AND revenue_impact > 1000000
ORDER BY timestamp DESC
LIMIT 10;
这类查询有一个非常值得强调的特点:它首先是一条分析查询,然后才是一条语义查询。
决定结果可用性的,不只是召回内容,更在于能否在高并发下完成复杂过滤与聚合、能否使用最新数据。这也是为何贴近主链路的往往不是单一向量系统,而是融合了上述能力的实时分析引擎。
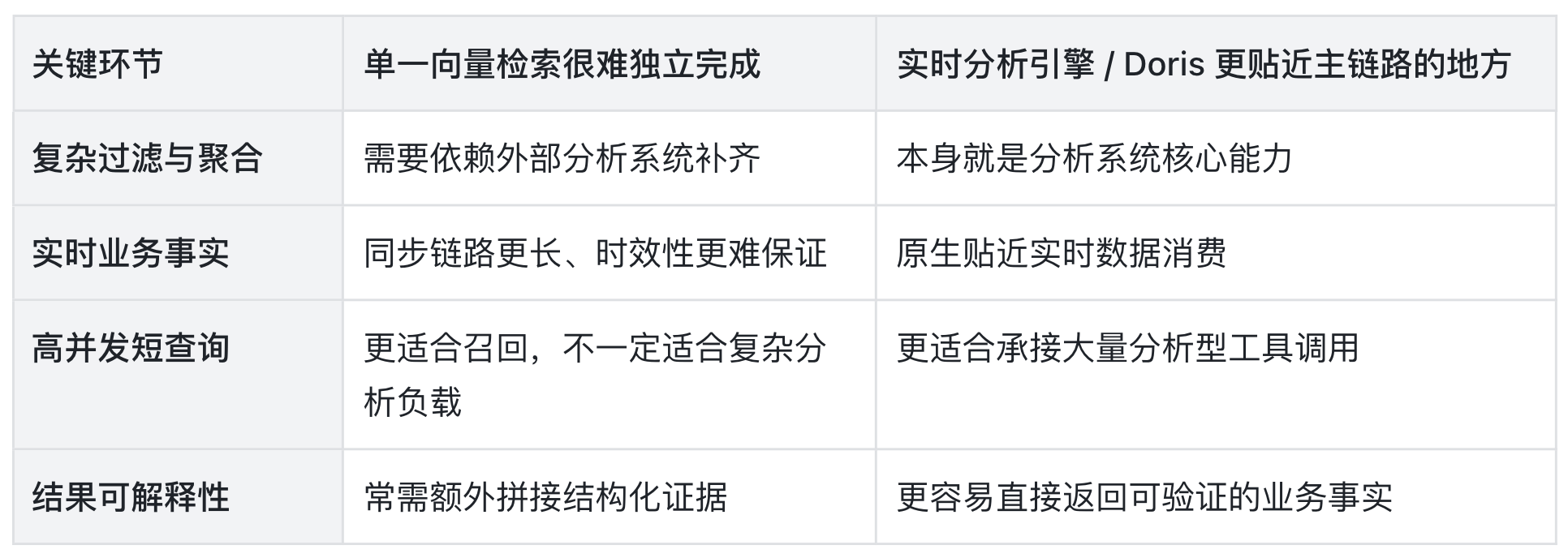
为什么 Apache Doris / SelectDB 会站到这个位置上?
回归业务视角,Apache Doris、SelectDB 能够脱颖而出,并非单纯因为接入了 AI,而是它原本就牢牢扎根在企业最关注的事实查询主链路上。
实时写入、低延迟查询、高并发分析、半结构化处理、多源统一访问,这些本来就是分析场景的刚需,在 Agent 时代被继承并无限放大。
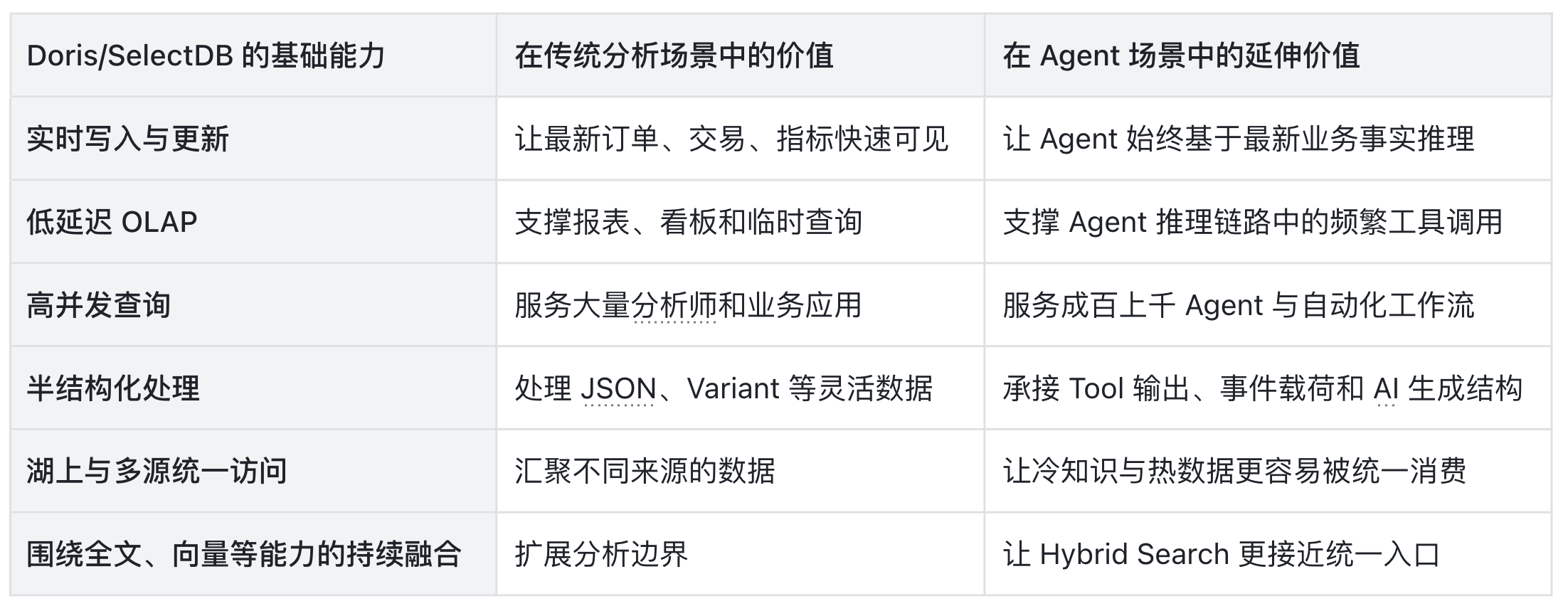
所以,当企业亟需一套既能做实时分析、又能承接多模态上下文的数据底座时,以 Apache Doris、SelectDB 为代表的系统恰好具备了成为前台统一入口的绝佳条件。
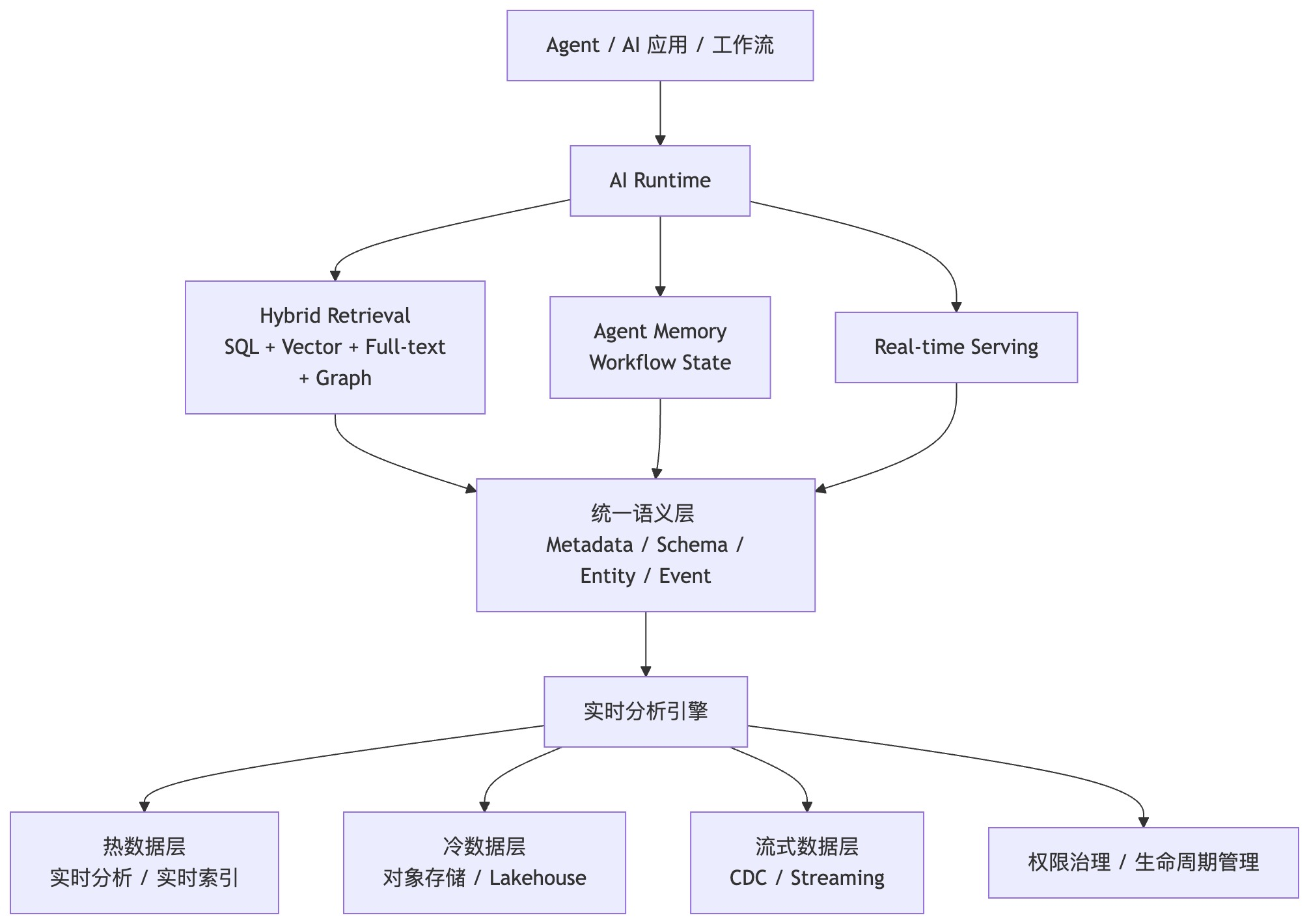
未来的数据平台:从分析引擎走向 Context Engine
在 Agentic 时代,数据平台的服务对象正转向 AI Runtime 本身。
它不再是一堆分散技术栈的拼凑,而更趋向于一套以实时分析引擎为中心,逐步向外融合结构化分析、全文、向量、流式处理和统一语义层的收敛架构。

在这种架构下,数据库的职责延展到了 Context Retrieval(上下文检索)、Hybrid Query Planning(混合查询规划)以及 Agent Memory(智能体记忆)。从工程实现来看:以成熟的实时分析引擎为中心向外扩展多模能力,远比强行把割裂的专有系统向内拼接,更具备现实落地性。
结语:重写实时分析的边界
从表面上看,多模数据管理像是在谈更多数据类型;但如果从企业最真实的落地路径看,它其实是在重写实时分析的边界。
过去,分析系统主要负责回答人的问题;未来,它必须时刻准备好回答 Agent 的问题,并在推理链路中承担起实时事实、统一查询和上下文供给的多重角色。
循着这个方向,像 Apache Doris、SelectDB 这样兼具极速分析能力,并持续向多模与统一查询能力演进的系统,理应成为最接近现实落地的核心数据基座。
SelectDB 产品发布会,开幕在即
在 6 月 11 日即将举行的 SelectDB 产品发布会上,我们将系统分享 Doris / SelectDB 在实时分析、混合检索、Agentic Analytics、AI Agent 可观测、多模数据处理等方向上的最新进展,也会系统呈现我们对下一代数据架构的系统思考。
欢迎关注 SelectDB 产品发布会——面向 Agent 的实时数据引擎。我们期待和大家一起讨论:Agent 时代的数据基础设施,究竟会走向哪里。
