过去一年,Agent 正从一个技术概念,逐渐变成企业智能化落地的核心入口。
这背后并不只是应用形态变化,更像是一场新的接口革命:人不再需要理解每一个工具的使用方式,也不再需要在不同系统之间反复切换;人只需要表达目标,Agent 则负责理解意图、拆解任务、选择工具、调用数据并完成执行。
在即将举行的 SelectDB 产品发布会上,我们也将围绕这一变化做一次更系统的分享:当 Agent 成为新的应用范式,企业的数据基础设施需要发生哪些改变?实时分析引擎在其中承担什么角色?
要回答这些问题,需要先从应用范式的演进说起。
一、Agent 时代正在到来
1990 年代的 Internet 上,有很多各自独立的应用:Email、FTP、Gopher、IRC、Telnet。它们有不同的协议,也有不同的客户端。Web 一开始只是其中一种,看起来只是一个用来浏览超文本的工具。
但后来的发展证明,Web 做了一件其他协议没有完成的事:它把很多应用吸收进来了。Webmail 逐渐替代了传统 Email 客户端,网页下载弱化了 FTP 的存在,Web 化的协作工具也重塑了即时通信的形态。Web 最终成为那个承载其他应用的应用。
Web 之所以能成功,不只是因为体验更好,而是因为它统一了“人”和“信息”的接口:一个 URL,一个浏览器,就可以访问几乎所有信息。这样的接口一旦建立起来,就很难再被逆转。
今天,Agent 与 LLM 的关系,也有一点类似。
LLM 的应用形态大致可以分为几类:直接调用、链式调用、RAG、Workflow、代码执行、Agent。但这并不是一个彼此平行的选项,Agent 更像是一种更高层的组织方式。
RAG 检索和代码执行,是 Agent 工具箱里的能力;预定义 Workflow,是 Agent 将决策路径“写死”之后的特例;直接调用,则是 Agent 在没有工具可用时最简单的形态。就像浏览器里可以发邮件、聊天、下载文件一样,Agent 内部可以检索知识、执行代码、串联推理、调用外部系统,甚至在关键节点请求人类把关。
它统一的是“人”和“能力”的接口:你不需要先判断该打开哪个系统、使用哪个工具、调用哪个 API;你只需要描述目标,Agent 会自己去规划、选择和执行。
这就是为什么我们说,Agent 时代正在到来。它不是一个短期热点,而是一个可能像 Web 重塑 Internet 一样,重塑软件应用形态的新范式。
二、软件的三种形态:从规则,到训练,再到驾驭
要理解 Agent 时代对数据基础设施意味着什么,我们需要先退一步,看清软件本身的演化逻辑。
过去几十年里,软件制造智能大致经历了三次变化。

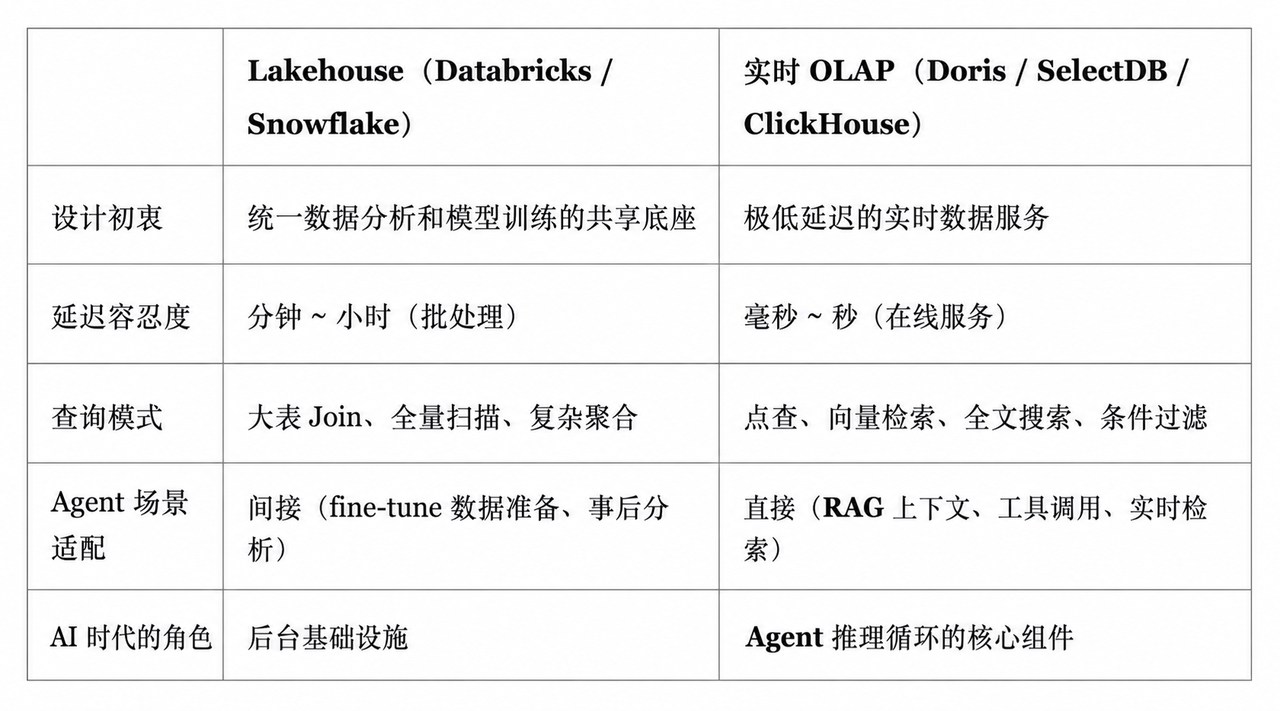
第一阶段,软件的核心是规则。工程师把业务逻辑写进代码,系统按照确定的规则执行。这个阶段的数据基础设施,主要是关系型数据库:存储状态,支持事务,保证业务系统稳定运行。
第二阶段,智能越来越多来自数据训练。企业把大量数据喂给模型,通过训练得到预测、推荐、识别等能力。这个阶段催生了 Lakehouse。企业需要一个统一底座,既能做 SQL 分析和 BI,也能支持 Spark、PyTorch 等工具做模型训练。Databricks 和 Snowflake 的崛起,正是抓住了这个需求。
而第三阶段正在改变这个前提。
当模型厂商(OpenAI、Anthropic、Google)完成了预训练,企业不再需要从零开始训练模型。核心工作流不再是洗数据 → 做特征 → 训练 → 部署,而是在推理时,用 200 毫秒这样极快的速度给 Agent 喂入最相关的上下文。
智能的来源变了,数据栈的重心自然也会随之变化。
三、Lakehouse 的核心假设正在松动
Lakehouse 过去最有吸引力的叙事,可以概括成一句话:一份数据,两种用途。
同一份存储在 S3 上的数据,既可以跑 SQL 又能做 BI 分析,也可以交给 Spark、PyTorch 等工具做模型训练。这个叙事在 2015 到 2022 年之间非常有说服力。那时候,很多企业都相信自己需要训练模型,分析团队和数据科学团队共享同一份数据底座,也确实有很强的工程价值。但进入 Agent 时代之后,这个叙事开始出现裂缝。
首先,训练和推理对数据系统的要求,本质上并不相同。
Lakehouse 更适合批处理场景。无论是基于开放表格式的数据管理,还是面向大规模扫描和离线计算的执行框架,本质上都服务于“夜间跑 ETL、白天出报表”或“大规模数据训练”的工作流。但 Agent 需要的不是批量处理一张拥有上百列的大宽表,而是在一次对话、一次推理、一次任务执行过程中,快速完成点查、过滤、聚合、向量检索、全文检索等操作。
对于 Agent 而言,数据查询不是后台任务,而是推理链路中的实时环节。
一次查询慢 200 毫秒还是 3 秒,对于传统报表用户来说也许差别不大;但对于一个需要多轮检索、多次调用工具的 Agent 来说,这可能就是 1 秒和 15 秒的差距。这会直接影响终端用户是否愿意继续等待。
Lakehouse 最强的能力,是分布式大规模扫描;但在 Agent 场景中,真正高频出现的是亚秒级查询、高并发轻查询、混合检索和语义化访问。这恰恰不是 Lakehouse 最擅长的部分。
其次,数据共享这个论点的说服力在下降。
Lakehouse 强调一湖多用,前提是分析团队和训练团队都需要访问同一份数据。但当企业的智能能力越来越多来自预训练大模型,而不是自研模型训练时,“训练团队”的核心工作流也在变化。
数据科学家仍然需要数据,但他们越来越多需要的是一份能够被实时查询、语义清晰、支持混合检索的热数据,而不是一份躺在 Parquet 文件里、等待 Spark 扫描的冷数据。
但这并不意味着 Lakehouse 会消失,它在企业数据治理、合规归档、PB 级冷数据管理,以及大模型厂商自身的预训练 Pipeline 中,依然有不可替代的价值。变化在于,它正在从前台的主角,变成更偏后台的基础设施。
而走向前台的,是那些能在 Agent 推理循环中直接创造价值的数据系统——实时 OLAP 引擎。
四、实时分析引擎正成为 Agent 时代的数据核心
当数据的首要消费者从"人"变成"智能体",整个分析型数据库的架构优先级会被重新定义。
第一,亚秒级延迟从加分项变成准入门槛
传统分析型数据库面对的是分析师。分析师可以等待报表刷新,可以接受查询排队,也可以在复杂分析中忍受一定延迟。但 Agent 面对的是终端用户。用户在对话窗口前等待回答,Agent 在后台不断拆解任务、调用工具、查询数据、补充上下文。每一次数据访问的延迟,都会被叠加到最终体验中。
这要求数据引擎在索引粒度和执行效率上做到极致。Short Key Index、ZoneMap、Bloom Filter、倒排索引等机制,不再只是性能优化手段,而是 Agent 能否稳定运行在实时场景中的基础能力。相比 Iceberg 的文件级跳过,Agent 场景更需要行级、块级、更细粒度的数据裁剪能力。
第二,混合检索需要一个统一入口
Agent 不会说"我现在要做一次向量检索",它只会说"帮我找到类似的情况"。一次对话中,Agent 可能先做一次点查,再做一次聚合分析,随后进行向量搜索,最后再通过全文检索补充证据。对 Agent 来说,这些都只是完成任务所需的能力。
但今天的技术生态往往是割裂的:向量数据库如 Pinecone 擅长相似度检索,但缺少完整的 SQL 分析能力;全文检索系统如 Elasticsearch 擅长关键词搜索,但在复杂分析和实时聚合上并不总是足够强;传统数仓擅长分析,却未必适合低延迟混合检索。
Agent 需要的是一个统一引擎:能够在同一个查询计划中调度 SQL、向量、全文等多种检索能力,合并结果,并以更适合 LLM 消费的方式返回上下文。Doris / SelectDB 正在这个方向上持续投入,将向量检索、全文检索与实时 SQL 分析能力进一步融合。
第三,Schema 语义化会成为数据库的一等能力
Text-to-SQL 的准确率,并不只取决于 LLM 的能力,也取决于 Schema 本身是否容易被机器理解。
在传统数仓中,类似 ods_usr_bhvr_pv_log_di 这样的表名,对熟悉业务的人来说可以通过数据字典理解;但对动态生成 SQL 的 Agent 来说,这样的 Schema 往往很难处理。
未来的数据库必须把“让机器理解数据结构”作为一等需求。表注释、列注释、示例数据、语义标签、指标口径、数据血缘,这些能力过去更多被视为治理和文档工作;但在 Agent 时代,它们会直接影响 Agent 是否能够正确理解数据、生成 SQL、调用工具并完成任务。
第四,高并发、低成本和细粒度弹性会变得更重要
一个分析师一天可能只写几十条 SQL。但一个 Agent 在一次复杂对话中,就可能生成几十条查询。企业内部一旦有大量 Agent 同时运行,查询量可能是过去分析场景的 100 倍,甚至 1000 倍。
这会对数据系统提出全新的挑战:不仅要快,还要能承受高并发;不仅要稳定,还要具备足够好的成本效率;不仅要能扩展,还要支持细粒度、秒级弹性。
一套为上百并发设计的 Lakehouse 集群,在面对成千上万 Agent 同时访问时,成本和延迟都可能变得难以控制。
这正是实时 OLAP 引擎需要解决的问题:在存算分离的基础上,通过共享存储架构、弹性计算资源和高效查询执行,支撑面向 Agent 的实时数据访问。这也是 Doris / SelectDB 持续演进的方向。
五、不是替代,是分层
这里需要特别精确:我们并不是说 Doris 替代 Databricks,也不是说实时分析引擎替代 Lakehouse。
真正发生的,是整个数据栈重心的迁移。
未来企业的数据架构更可能是一个两层结构:热数据在实时 OLAP 引擎,例如 Doris / SelectDB、ClickHouse,用于服务 Agent 的每一次实时查询,毫秒级返回;冷数据放在 Lakehouse 中,Lakehouse 本身构建在对象存储之上,天然适合承载长周期归档、合规备份和历史数据分析。
Lakehouse 的价值不会消失,开放格式、数据共享、治理、ACID 这些能力依旧重要,但它不再是数据世界的中心。当 Agent 每天产生数百万次实时查询,而训练任务可能一周才跑一次时,哪个引擎最能捕获增量价值,答案已经很清楚。
Agent 正在重塑应用层。实时分析引擎,正在成为 Agent 时代数据栈中最关键的实时入口。
在这样的背景下, Doris / SelectDB 和 ClickHouse 这类实时分析引擎,正在从“可选项”变成企业智能化架构中的“默认配置”。
六、结束语
Agent 时代不是一个停留在概念里的趋势。它正在以一种渐进但明确的方式进入企业:先从客服、运营、BI、知识库、数据分析等场景开始,再逐步扩展到更多核心业务流程。
可以确定的是,当 Agent 真正进入生产系统,企业对数据基础设施的要求会发生根本变化。实时、低延迟、混合检索、语义化、高并发、低成本弹性,这些过去看起来分散的能力,将会汇聚成 Agent 时代的数据底座。
在即将举行的 SelectDB 产品发布会上,我们将进一步分享 Doris / SelectDB 在实时分析、混合检索、Agentic Analytics、AI Agent 可观测、多模数据处理等方向上的最新进展,也会系统呈现我们对下一代数据架构的系统思考。
欢迎关注 SelectDB 产品发布会——面向 Agent 的实时数据引擎( 6月11日,14:00,视频号:SelectDB )。我们期待和大家一起讨论:Agent 时代的数据基础设施,究竟会走向哪里。



