摘要:
本文从 AI Agent 日志观测切入,讨论 JSON 分析为什么重要:Agent Trace、Tool Call、RAG 检索结果、Prompt 和 Reasoning 具有嵌套结构与动态 Schema,既不能简单拍平,也不适合只当 String 存储。因此,如何保留 JSON 灵活性的同时,获得列式存储的查询性能,成为 Agent Observability 的关键问题。
如果想进一步了解数据库底层如何支撑这类高稀疏、高演进的宽 JSON 场景,推荐阅读《Doris 4.1:面向万级宽 JSON 的 Doc Mode 与 Segment V3》。
传统应用日志通常是扁平结构,记录的无非是时间、级别、服务名、错误码和耗时。其特点是:事件边界清晰、调用链相对固定、字段稳定。一条日志就是一个独立事件,日志之间通常靠request_id或 trace_id 简单串联起来。
但到了 AI Agent 场景,这套模型很快就不够用了。
由于 Agent 的执行逻辑是非确定性的,一次 Agent 请求内部,一次完整的请求往往包含多轮的逻辑推理(Reasoning)、多次外部工具调用(Tool Call)、向量检索甚至是子 Agent 间的交互。 排障的核心诉求,不再是简单的定位报错,而是深度的归因分析:
- Agent 为什么在这个节点做出了这个决策?
- 哪一步 Reasoning 出现了幻觉?
- 发送给大模型的 Prompt 是如何被动态拼接的?
- Token 消耗为什么突然暴涨?
- ......
像 LangSmith、Langfuse 这样的现代观测平台,已经将 Agent Trace 定义为一棵包含完整上下文的执行树。这意味着:Agent 观测的核心目标,已经从“记录结果”转变为“还原过程”。 面对这种高度复杂的执行语义,传统只适合聚合统计的扁平日志模型,显然已经无法适用。
1. 全量拍平:难以还原嵌套树、面临频繁的 DDL
面对海量且复杂的 Agent 日志,很多团队在处理时,第一反应是将字段拍平存入大宽表。但这其实会有 2 个关键问题:
首先,强行降维会破坏关键的嵌套执行树。
在 Agent 场景中,JSON 不仅仅是一种数据传输格式,它最大的优势在于能够极其自然地将消息、工具参数、检索结果和执行流串联起来。一次请求中,往往包含着数组(如多轮对话)和树状结构(如嵌套的 Spans)。
以下为典型的 Agent Span 示例:
{
"trace_id": "tr-xyz-123",
"span_id": "sp-456",
"tool_call": {
"tool_name": "execute_shell",
"args": {
"command": "grep -r 'todo' .",
"timeout_ms": 5000
}
},
"reasoning_step": [
{"thought": "Need to search codebase for missing items"},
{"action": "Calling execute_shell"}
]
}
查询阶段,部分字段当然可以拍平,比如 tool_name、latency、token_usage 这些指标字段。但对于 reasoning_step(数组)或带有层级关系的子 Span 而言,如果在数据入库时就强行丢弃其原有的 JSON 树状结构,后续的步骤回放、上下文关联和 JSON Path 细粒度查询都会变得极其困难。Agent 日志首先是具备上下文关系的执行记录,其次才是分析对象。
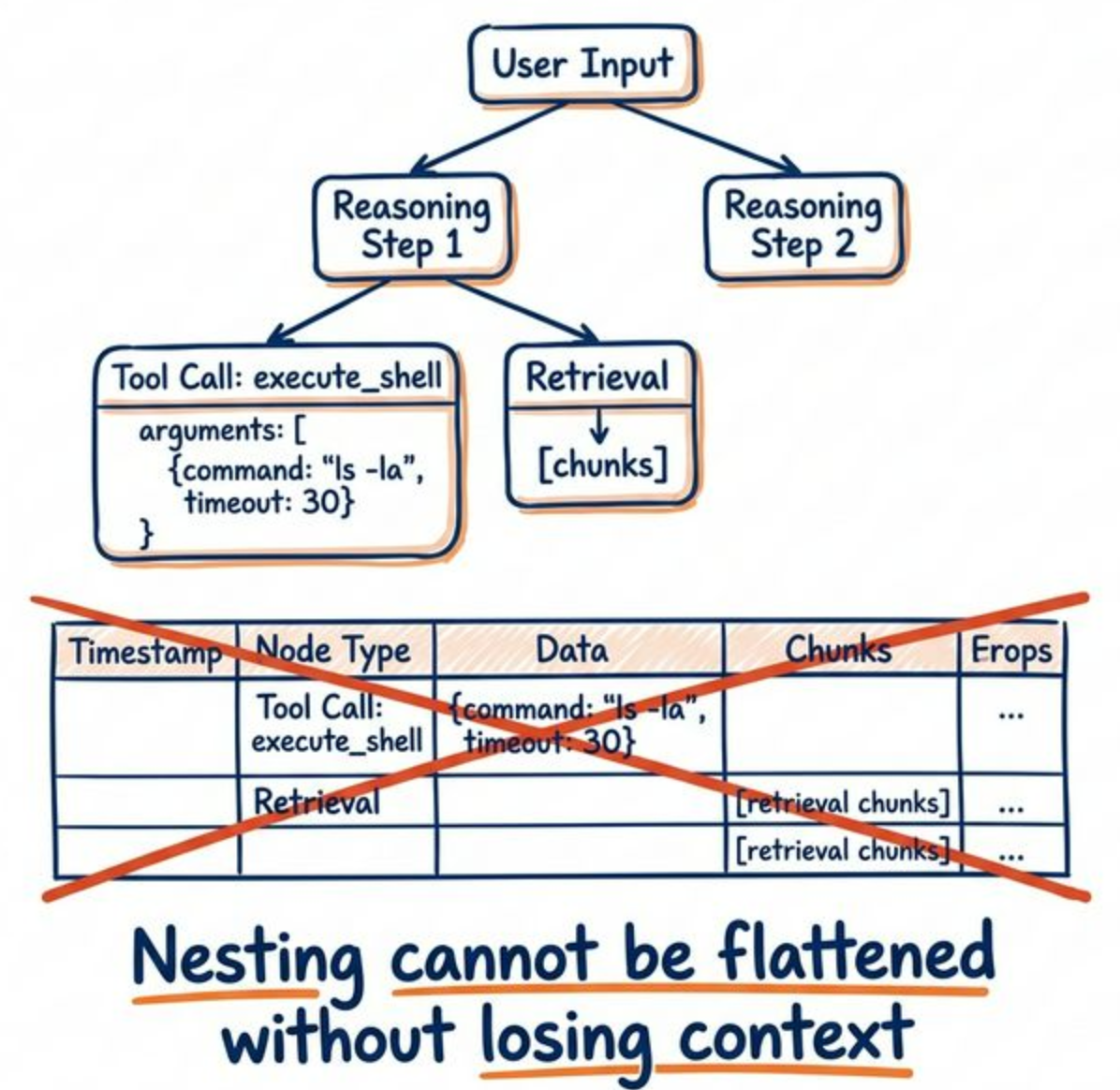
其次,Schema 的演进速度极快。
Agent 业务迭代极快。比如,今天记录的是 tool_name,明天可能就会新增 retrieval_chunks(检索分块)、guardrail_verdict(护栏校验结果)或 reasoning_budget。如果采用固定列的强 Schema 模式,数据库表结构将会被频繁的 DDL(ALTER TABLE)操作拖垮。
2. 直接作为 String 存储:难以应对大规模 JSON 分析
既然拍平不可取,很多系统图省事,直接将整段 JSON 作为 String 存入数据库。能跑通吗?能。但这就相当于把数据变成了一个只能落盘、极难分析的黑盒。
先看一个典型的排障灾难案例:
假设一张 AI Agent 日志表每天写入几十亿条事件,日志 payload 全部以 String 方式保存。某天,线上某个 MCP 工具错误率突然升高,研发想快速排查最近 1 小时内
tool_name='retrieve_docs'的请求,按模型版本、租户和错误类型做聚合,并拉出 P95 延迟。
表面上这只是一次很常见的观测分析,但由于这些字段都藏在 String 里,查询引擎的优化器对此一无所知。它无法做谓词下推和数据裁剪,只能先把整段 JSON 从存储里读出来,再对每一行反复做 JSON_EXTRACT 或类似函数解析。
结果就是:真正符合条件的目标数据可能仅占 0.1%,但系统却迫做了一次全表扫描(Full Scan)。 为了查一个 1 小时内的异常工具,扫掉了几 TB 的数据,磁盘 IO 被打满,CPU 全耗在极其昂贵的 JSON 解析上,查询延迟极高,甚至直接把整个集群拖垮。
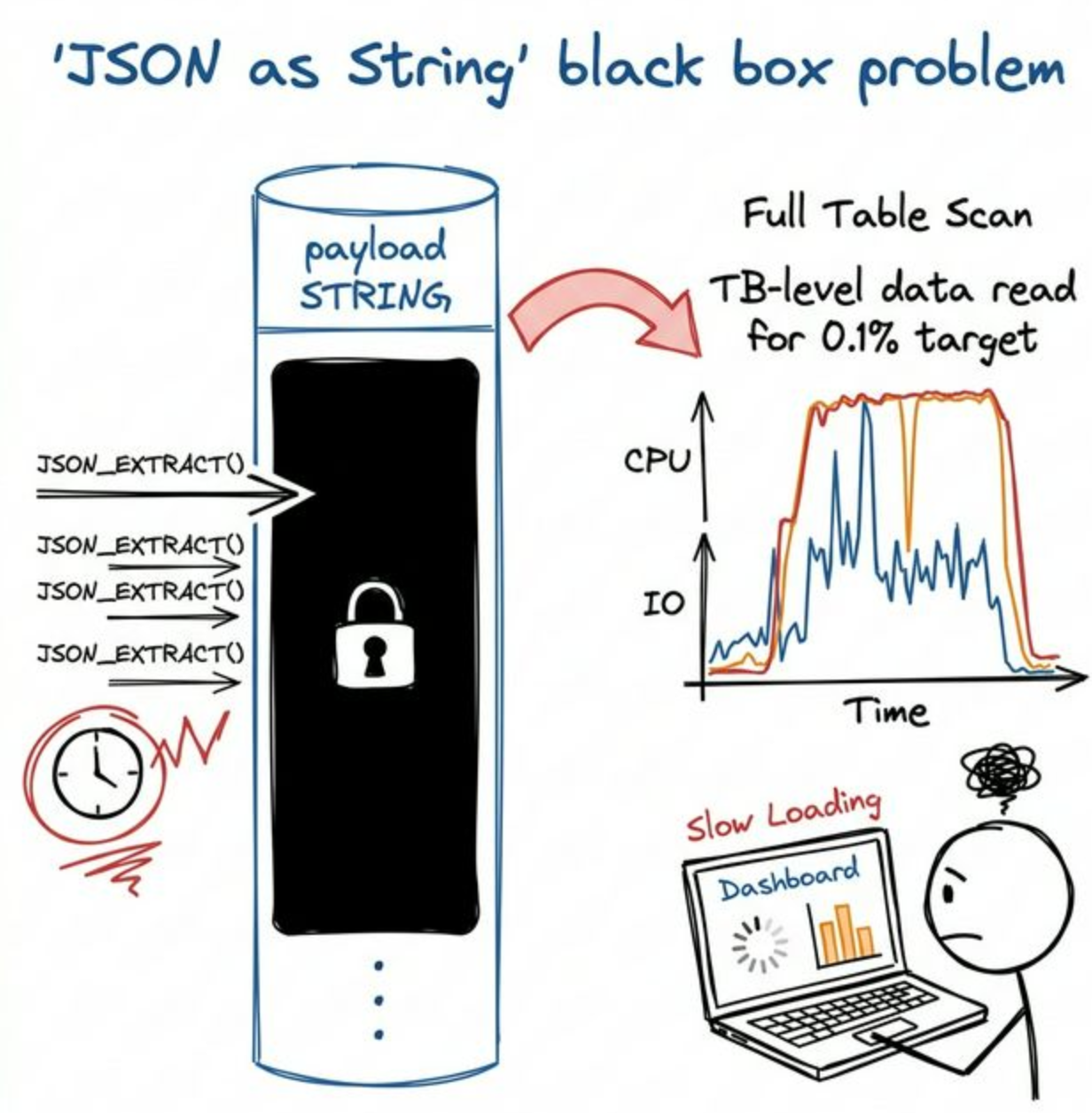
在 Apache Doris、Clickhouse 等官方文档中对此边界已定义的很清楚:如果只做整条写入和原样读取,String 足够了;但若要对动态 JSON 内部的层级做高并发的 OLAP 分析,String 会成为极大的瓶颈。此时,即便你转向 MongoDB 或 PostgreSQL 这样的纯文档数据库,也无法应对 TB 级别的复杂聚合分析诉求。
3. 半结构化原生支持,兼顾 JSON 灵活性与列式查询性能
既然拍平不能用,String 查不动,那完美的解法是什么?答案是:让数据库去适应 JSON,而不是让 JSON 去迁就数据库。
这要求现代数据仓库必须具备一种“既有半结构化灵活性,又有强类型列式性能”的能力。例如 ClickHouse 的 JSON 类型或 Doris / SelectDB 的 VARIANT 类型。
3.1 自动子列提取(Auto-Subcolumn Extraction)
它们不再将 JSON 视为死板的文本。当写入数据时,底层存储引擎如果检测到 payload["tool_args"]["command"] 这个 JSON Path 频繁出现,它会自动在底层将其提取,并在物理上单独存储为一个独立的列。
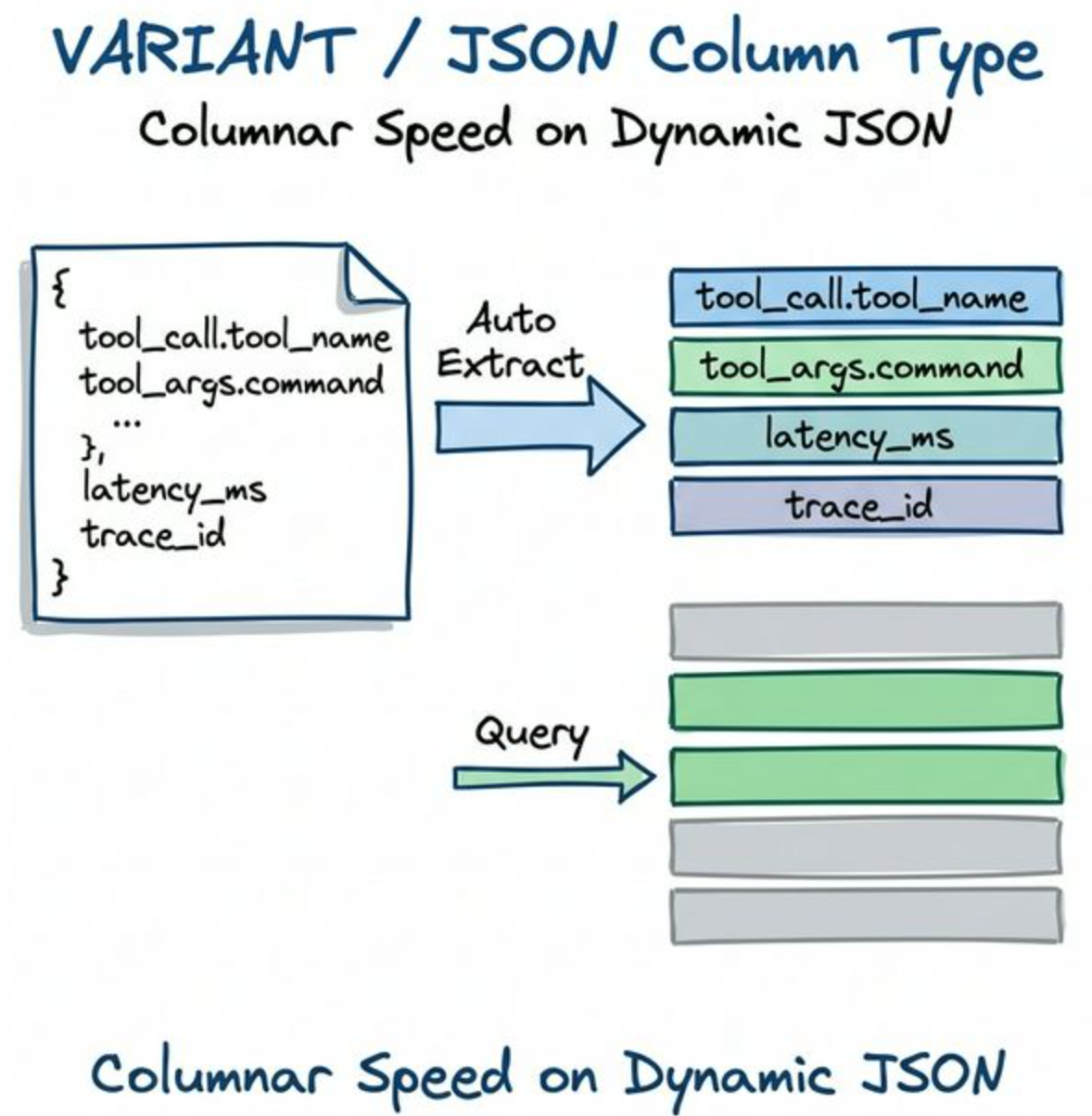
这意味着,你拥有了和传统列式存储一样极致的扫描性能与压缩率。在 Doris 中,即使你的数据是以动态 JSON 写入的,查询语句依然简洁且高效:
-- 直接基于 VARIANT 数据类型的高效 列裁剪 + 谓词下推
SELECT
payload["tool_call"]["tool_name"] AS tool,
AVG(cast(payload["latency_ms"] as int)) AS avg_latency
FROM agent_traces
WHERE payload["trace_id"] = 'tr-xyz-123'
GROUP BY 1
ORDER BY avg_latency DESC;
有了这种机制,原本的文本黑盒瞬间变成了可裁剪、带加速且 Schema Free 的列式数据对象。
3.2 倒排索引(Inverted Index)
除了聚合分析,排障时最高频的操作是根据关键字捞取具体的 Bad Case(例如:查哪次对话触发了 permission denied 报错,或哪条 Prompt 包含特定的业务实体)。
面对 TB 级别的长文本,传统的 LIKE 会导致全表扫描。现代分析型引擎引入了原生的倒排索引或 NGram 索引能力:
- 针对长文本字段:将
prompt、completion或error_message这样的长文本独立建倒排索引,体验类似于 ElasticSearch 的原生MATCH检索。 - 针对 JSON/VARIANT 整体:只要关键字在 JSON 中存在,就可以体验到毫秒级的精准捞取能力。
在 Doris 这种兼具 Variant 列和倒排索引的引擎中,可以同时享受列式聚合和全文检索的双重优势:
-- 既能按深度JSON path筛选,又能通过全文检索加速捞取具体的 Bad Case
SELECT
payload["trace_id"],
payload["reasoning_step"]
FROM agent_traces
WHERE
-- 结构化子JSON path过滤
payload["tool_call"]["tool_name"] = 'execute_shell'
-- 结合倒排索引进行全文关键字检索 (无需全表 LIKE)
AND payload["error_msg"] MATCH_ANY 'timeout'
AND payload["prompt"] MATCH_ALL 'delete users table';
4. AI Agent 日志的混合建模最佳实践
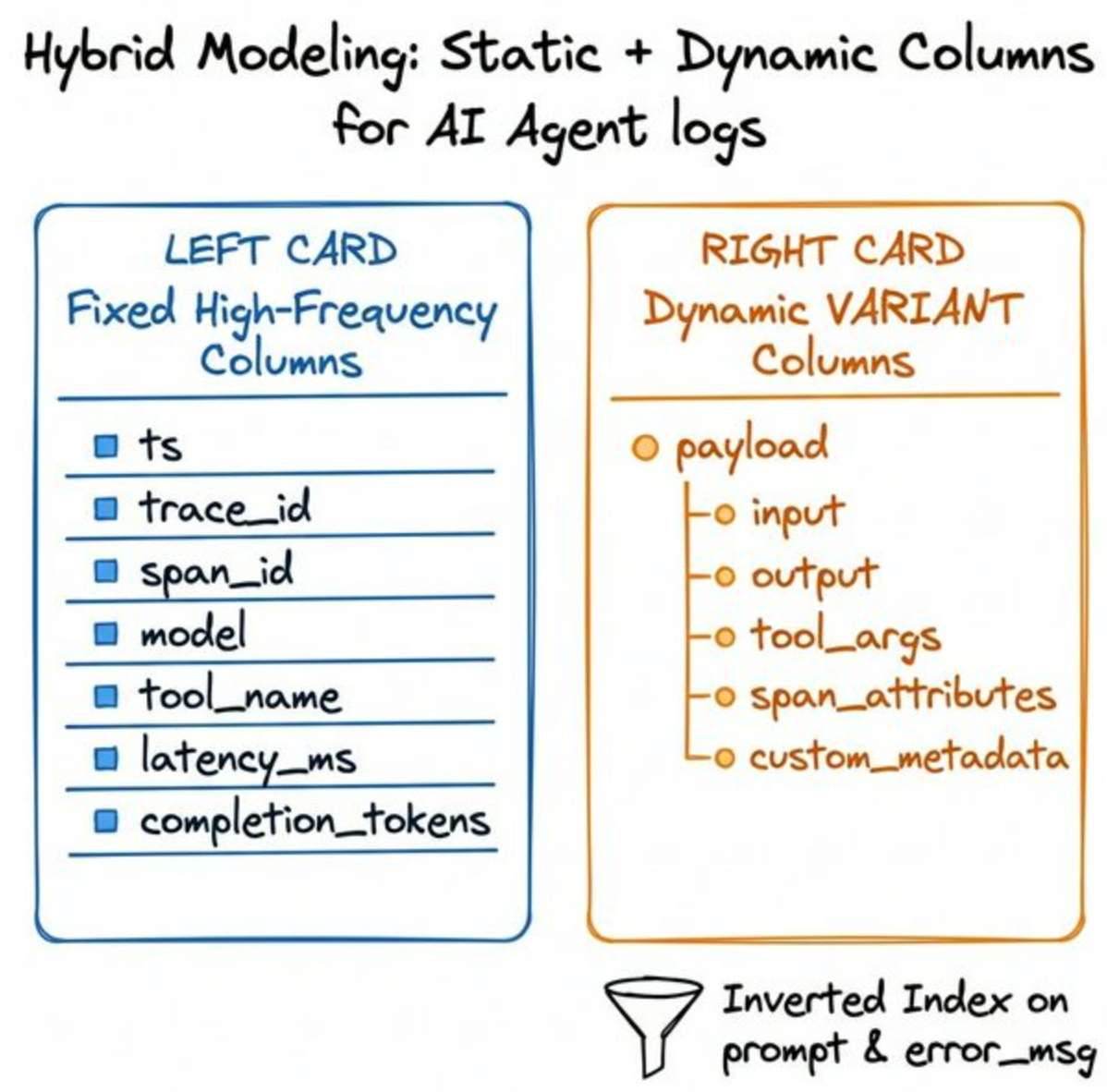
在生产环境真正落地时,不建议走全部 JSON 拍平列(Flatten)或者全文档用单列(String)的极端路线。比较稳健的架构是动静分离的混合建模:
A. 高频标量选择普通列大宽表:把 ts、trace_id、span_id、parent_span_id、model、tool_name、latency_ms、completion_tokens 等固定且高频的过滤/聚合维度设为标准列。
B. 动态对象选择半结构化 VARIANT 列:把 input、output、tool_args、span_attributes、custom_metadata 等层级深、Schema 容易变的内容放进 VARIANT 类型列,由底层引擎执行子列提取加速;同时对需要排障的关键说明字段开启倒排索引(Inverted Index)。
标准的 Doris 混合建模建表与查询示例:
为了支撑上述混合建模方案,下面给出了一套标准的数据定义(DDL)与查询(DML)示例。在企业级生产环境中,海量 Agent 日志的写入与存储往往需要占用庞大的基础设施资源。
为了降低自建集群的运维难度,很多团队会选择 Apache Doris 的商业化版本 SelectDB。SelectDB 在完整继承了 VARIANT 动态推导和倒排索引等分析能力的基础上,采用了存算分离的云原生架构。这使得海量历史日志可以低成本地长期保存在对象存储中,计算资源也能按需弹性扩缩容,研发团队只需专注于日志查询与业务排障,而无需担忧底层的集群扩缩容和性能调优。
建表语句 (DDL)
利用 Variant + 倒排索引的完整建表 DDL:
CREATE TABLE agent_trace_logs (
`ts` DATETIME NOT NULL COMMENT "日志时间",
`trace_id` VARCHAR(128) NOT NULL COMMENT "全链路追踪 ID",
`span_id` VARCHAR(128) NOT NULL COMMENT "当前步骤 ID",
`tool_name` VARCHAR(64) COMMENT "工具名称",
`latency_ms` INT COMMENT "耗时",
-- 核心:动态不可预知的嵌套结构全扔给 VARIANT
`payload` VARIANT NULL COMMENT "动态上下文与嵌套执行流",
-- 为经常用于全文捞取的字段加上倒排索引,加速 MATCH 查询
INDEX idx_payload_prompt (`payload["prompt"]`) USING INVERTED PROPERTIES("parser" = "english"),
INDEX idx_payload_error (`payload["error_msg"]`) USING INVERTED PROPERTIES("parser" = "english")
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `trace_id`) -- 优化时间范围和链路查询的排序键
PARTITION BY RANGE(`ts`) ()
DISTRIBUTED BY HASH(`trace_id`) BUCKETS AUTO
PROPERTIES (
....
);
分析查询语句 (DML)
复杂 JSON 写入到 payload 之后,我们可以直接这样像 Python 语法访问 JSON 一样,用 JSON path 访问数据:
-- 业务诉求:找出最近一天里,调用过 'execute_shell' 工具,耗时大于 1秒,且报错信息里包含 'permission denied' 的 trace 记录
SELECT
trace_id,
tool_name,
latency_ms,
payload["tool_args"]["command"] AS executed_command,
payload["error_msg"] AS error_detail
FROM agent_trace_logs
WHERE ts > now() - INTERVAL 1 DAY
AND tool_name = 'execute_shell'
AND latency_ms > 1000
AND payload["error_msg"] MATCH_ALL 'permission denied'
ORDER BY latency_ms DESC
LIMIT 50;
这一组合兼顾了结构聚合、Schema free 以及毫秒级日志检索三个维度的诉求。
5. 结语
JSON 对于 Agent 日志观测的重要性,由其底层业务逻辑决定:Agent 的执行流天然是半结构化的,包含大量层级、数组和不断变化的 Schema。

相较于全存纯文本 String(牺牲性能)或强行拍平列式化(牺牲扩展性),保留 JSON 的原始结构并交由底层引擎做自动列式推导,能完美兼顾 Schema 的灵活度与 OLAP 的极速性能。这也就是为什么在构建 Agent 观测底座时,诸如 Apache Doris 以及具备云原生存算分离架构的 SelectDB 等系统,正逐渐成为诸多开发团队务实且高效的架构选项。
另外,如果想进一步了解数据库底层如何支撑这类高稀疏、高演进的宽 JSON 场景,可以阅读《Doris 4.1:面向万级宽 JSON 的 Doc Mode 与 Segment V3》。这篇文章会从 Doc Mode、Segment V3 等机制出发,解释 Doris 如何优化宽 JSON 的写入、存储和查询性能。


