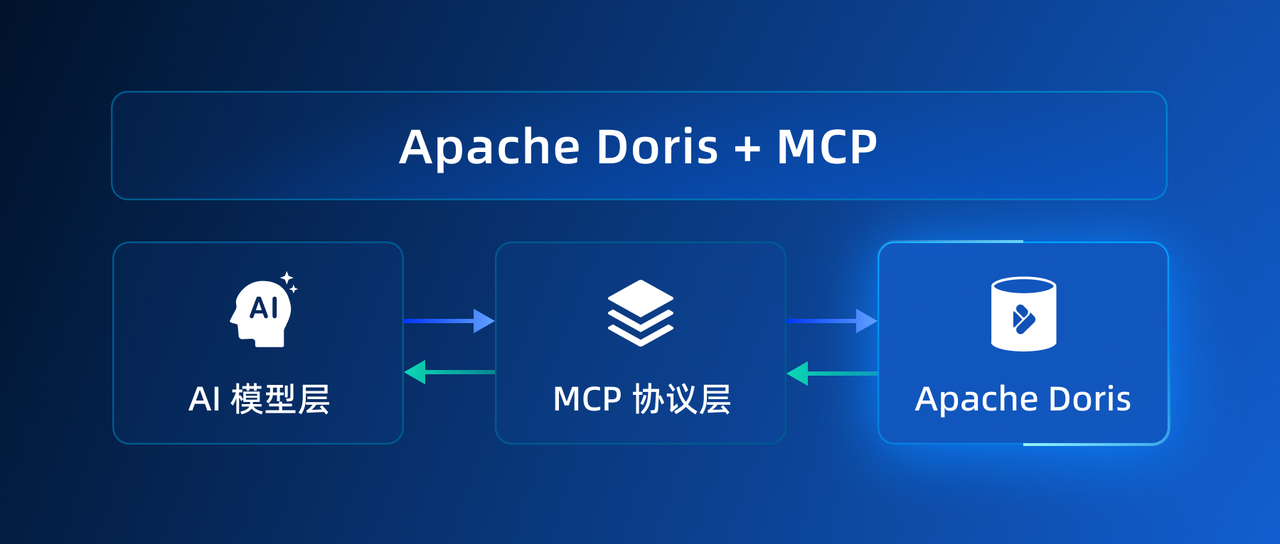
随着大语言模型(LLM)的普及,检索增强生成(RAG)技术成为解决大模型知识时效性、准确性问题的核心方案,通过引入外部知识库,为模型提供实时、可控的上下文,从而提升回答的准确性与可解释性。
然而,在实际落地过程中,RAG 的效果不仅取决于模型能力,更强地依赖底层数据系统的支撑能力。传统数据库或单一向量数据库,往往难以同时满足向量检索、关键词过滤、结构化分析以及高并发查询等多维需求,导致系统复杂度高、性能瓶颈明显。
Apache Doris 作为一款高性能 MPP 架构的实时分析型数据库,具备统一的混合检索与分析能力(HSAP),融合向量检索与全文搜索能力,有效降低系统复杂度并提升整体性能,可作为构建 RAG 系统的重要数据基础设施。
本文将结合实战案例,详细讲解如何基于 Apache Doris 搭建完整的 RAG 系统,涵盖环境准备、数据处理、向量入库、检索问答全流程,并讨论传统 RAG 系统的局限和一些应对方法。
相关实践:Doris & SelectDB for AI 实战:从零搭建非结构化数据智能分析洞察系统
本文示例基于 Apache Doris 展开,便于读者理解底层能力与具体实现机制。在实际生产环境中,如果更关注云上托管、弹性扩缩容、企业级治理与运维效率,也可以选择 SelectDB 作为托管方案(selectdb.com)。SelectDB 是基于 Apache Doris 构建,提供 Cloud 与 Enterprise 等产品形态,能够帮助企业更快完成 AI 检索、实时分析与数据服务场景的落地。
1. 环境准备
构建本次 RAG 系统的核心组件如下:
-
LLM 引擎:Deepseek API(负责对话交互与答案生成)
-
嵌入模型:Ollama + bge-m3:latest(生成文本向量嵌入)
-
向量数据库:Apache Doris(存储文本片段与向量,支持 ANN 检索)
-
文本处理:LangChain(文本分片、嵌入生成)
-
数据处理:Pandas(数据格式转换)
2. 部署与建表
首先需完成 Apache Doris 的安装部署,具体步骤可参考官方文档。部署完成后,创建用于 RAG 系统的数据库和向量表:
-- 创建数据库
CREATE DATABASE doris_rag_test_db;
USE doris_rag_test_db;
-- 创建向量表(支持 HNSW 索引的 ANN 检索)
CREATE TABLE `doris_rag_demo` (
`id` int NULL,
`content` text NULL,
`embedding` array<float> NOT NULL,
-- 构建 HNSW 向量索引,适配 1024 维向量的内积计算
INDEX idx_embedding (`embedding`) USING ANN PROPERTIES(
"dim" = "1024",
"ef_construction" = "40",
"index_type" = "hnsw",
"max_degree" = "32",
"metric_type" = "inner_product"
)
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
3. 构建可检索知识库(离线数据处理)
3.1. 文本分片(Chunking)
长文本直接嵌入会导致向量表征失真,需先进行分片处理。本文采用 LangChain 的 RecursiveCharacterTextSplitter 实现带重叠的文本分割,保证上下文连续性:
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 定义分片规则:chunk_size=400 字符,重叠 10 字符
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400, chunk_overlap=10, length_function=len
)
# 待处理的 Doris 文档文本(完整文本见附件)
text = """
Apache Doris 简介
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库...(完整文本省略)
"""
# 执行分片
chunks = text_splitter.split_text(text)
print(f"文档分片完成,共生成 {len(chunks)} 个文本片段")
3.2 向量嵌入生成
使用 Ollama 部署的 bge-m3 模型将文本片段转换为 1024 维向量,该模型在中文文本表征上具备优异性能:
from langchain_community.embeddings import OllamaEmbeddings
import pandas as pd
# 初始化嵌入模型(需本地启动 Ollama 服务,端口 11434)
embeddings = OllamaEmbeddings(model='bge-m3:latest', base_url='http://localhost:11434')
# 为每个分片生成 ID、文本内容、向量
docs = []
cur_id = 1
for chunk in chunks:
docs.append({
"id": cur_id,
"content": chunk,
})
cur_id += 1
# 批量生成向量
contents = [d["content"] for d in docs]
vectors = embeddings.embed_documents(contents)
# 组装成 DataFrame 便于后续导入 Doris
df = pd.DataFrame([
{
"id": d["id"],
"content": d["content"],
"embedding": vec,
}
for d, vec in zip(docs, vectors)
])
print("向量生成完成,数据示例:")
print(df[["id", "content"]].head(2))
3.3 向量数据导入 Doris
通过 Doris 向量客户端将包含文本和向量的数据导入已创建的表中:
from doris_vector_search import DorisVectorClient, AuthOptions, IndexOptions
# 配置 Doris 连接信息
auth = AuthOptions(
host='localhost',
query_port=9030,
http_port=8030,
user='root',
password='', # 实际环境请配置密码
)
# 初始化客户端并导入数据
client = DorisVectorClient('doris_rag_test_db', auth_options=auth)
index_options = IndexOptions(index_type="hnsw", metric_type="inner_product")
table = client.create_table(
'doris_rag_demo',
df,
index_options=index_options,
)
print("数据成功导入 Doris 向量表!")
4. 在线检索与答案生成
4.1 向量检索
接收用户查询后,先将查询文本转换为向量,再通过 Doris 的 ANN 索引检索最相关的文本片段:
# 用户查询问题
query = "doris支持哪些存储模型?"
# 生成查询向量
query_vec = embeddings.embed_query(query)
# 检索 Top5 相关片段
df_search = (
table.search(query_vec)
.limit(5)
.select(["id", "content"])
.to_pandas()
)
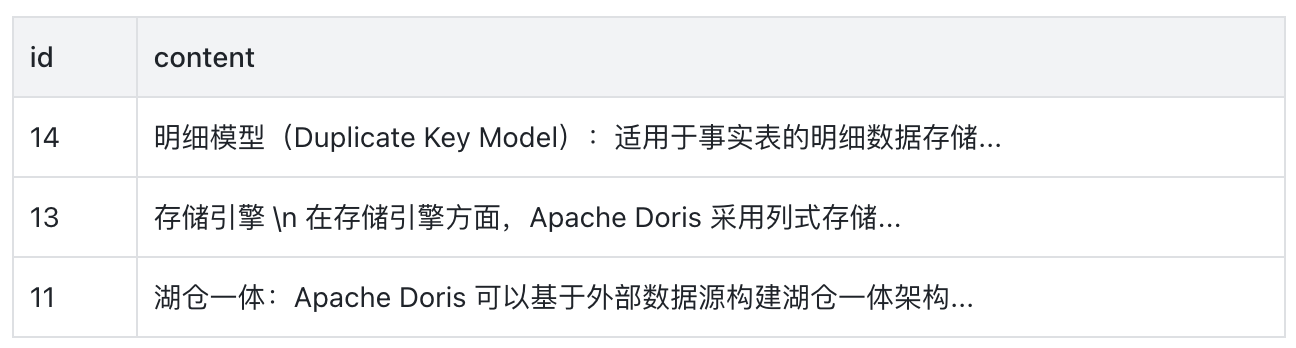
print("检索到的相关文本片段:")
for idx, row in df_search.iterrows():
print(f"\n【片段 {idx+1}】\n{row['content']}")
检索结果示例:
4.2 结合 LLM 生成答案
将检索到的文本片段作为上下文,拼接成提示词后调用 LLM API 生成相对准确的答案:
from langchain_openai import ChatOpenAI
# 拼接上下文
ctx = "\n".join(f"{r['content']}" for _, r in df_search.iterrows())
prompt = f"""以下是检索到的 Doris 文档片段:
{ctx}
请根据上述内容回答:{query}"""
# 初始化 Deepseek LLM
llm = ChatOpenAI(
model='deepseek-v3-1-terminus',
api_key='your_api_key', # 替换为实际 API Key
base_url='https://ark.cn-beijing.volces.com/api/v3',
temperature=1.0, # 控制回答随机性
)
# 生成答案
resp = llm.invoke(prompt)
print("最终回答:")
print(resp.content)
最终生成的答案示例:
Apache Doris 支持多种针对性优化的存储模型,核心包括:
- 明细模型(Duplicate Key Model):适用于事实表的明细数据存储;
- 主键模型(Unique Key Model):保证 Key 唯一性,相同 Key 数据会被覆盖,支持行级别更新;
- 聚合模型(Aggregate Key Model):相同 Key 的 Value 列会合并,提前聚合提升查询性能。
此外,Doris 还支持宽表模型、预聚合模型、星型 / 雪花模型等建模方式,适配不同业务场景需求。
至此,一个基础的 RAG 系统已经搭建完成,但该系统仅支持较为简单的知识查询问题,面对复杂的逻辑关系和多实体关联时,将面临知识碎片化、难以有效处理复杂问题、信息利用率低等问题。在此基础上,我们可以将结构化的实体关系知识与基础 RAG 结合,让 LLM 能基于完整的知识关联回答复杂问题。
5. 知识图谱增强 RAG 设计思路
知识图谱一般构建流程包括:
-
实体抽取:使用 LLM 从文本中识别和提取实体,如人物、地点、组织、概念等。
-
关系抽取:识别实体之间的关系,构建三元组(头实体-关系-尾实体)。
-
图谱构建:将实体和关系组织成图结构,存储在图数据库中。
-
向量化:将图谱子结构转换为向量,支持语义检索。
基于 Doris 构建的核心思路是将非结构化的文档转换为结构化的知识图谱(实体 + 关系),并将知识图谱数据存入 Doris 做持久化存储,查询时先检索知识图谱的实体关系,再基于完整的结构化知识生成答案,核心步骤如下:
- 通过 LLM 从文档分片中抽取实体和实体间的关系;
- 用 NetworkX 将抽取的信息构造为图结构,并通过 Pyvis 实现可视化;
- 将知识图谱的实体、关系数据生成向量,存入 Doris 的
graph_chunk表; - 接收到用户查询后,先检索知识图谱的相关实体,再查询实体间的关系,构造子图;
- 基于知识图谱的子图信息,让 LLM 生成精准、全面的答案。
5.1 实体与关系的抽取
利用 LLM,通过定制化提示词从 Doris 文档分片中抽取实体和关系,实体类型限定为Organization/ Person/ Location/ Event/ Concept,关系需包含源实体、目标实体、关系描述、关系强度:
def build_extract_prompt(text: str) -> str:
"""构建实体关系抽取的提示词"""
return f"""
目标:从文本中识别指定类型的实体和实体间的关系,使用中文输出,不翻译。
实体类型:[Organization, Person, Location, Event, Concept]
步骤1:抽取实体,格式为:("entity"<|><实体名><|><实体类型><|><实体描述>)
步骤2:抽取关系,格式为:("relationship"<|><源实体><|><目标实体><|><关系描述><|><关系强度(0-1)>)
要求:仅输出实体和关系,无其他额外文本、解释。
输入文本:{text}
"""
# 选取Doris文档中关于发展历程、应用现状的分片(实体关系密集)
graph_text = chunks[0] + chunks[1] + chunks[2]
# 构建提示词并调用LLM抽取
prompt = build_extract_prompt(graph_text)
resp = llm.invoke(prompt)
extract_result = resp.content.strip()
print("实体关系抽取结果(部分):\n", extract_result[:500])
实体关系抽取结果示例(部分):
("entity"<|>Apache Doris<|>Organization<|>一款基于MPP架构的高性能、实时分析型数据库...)\n
("entity"<|>百度<|>Organization<|>一家互联网公司,Apache Doris最初是其广告报表业务的Palo项目...)\n
("entity"<|>Apache基金会<|>Organization<|>支持开源软件项目的非营利组织,2018年接受百度捐赠的Doris...)\n
("relationship"<|>Apache Doris<|>百度<|>Apache Doris最初是百度广告报表业务的Palo项目,由百度捐赠给Apache基金会<|>0.9)\n
("relationship"<|>百度<|>Apache基金会<|>百度于2018年7月将Apache Doris捐赠给Apache基金会<|>0.8)
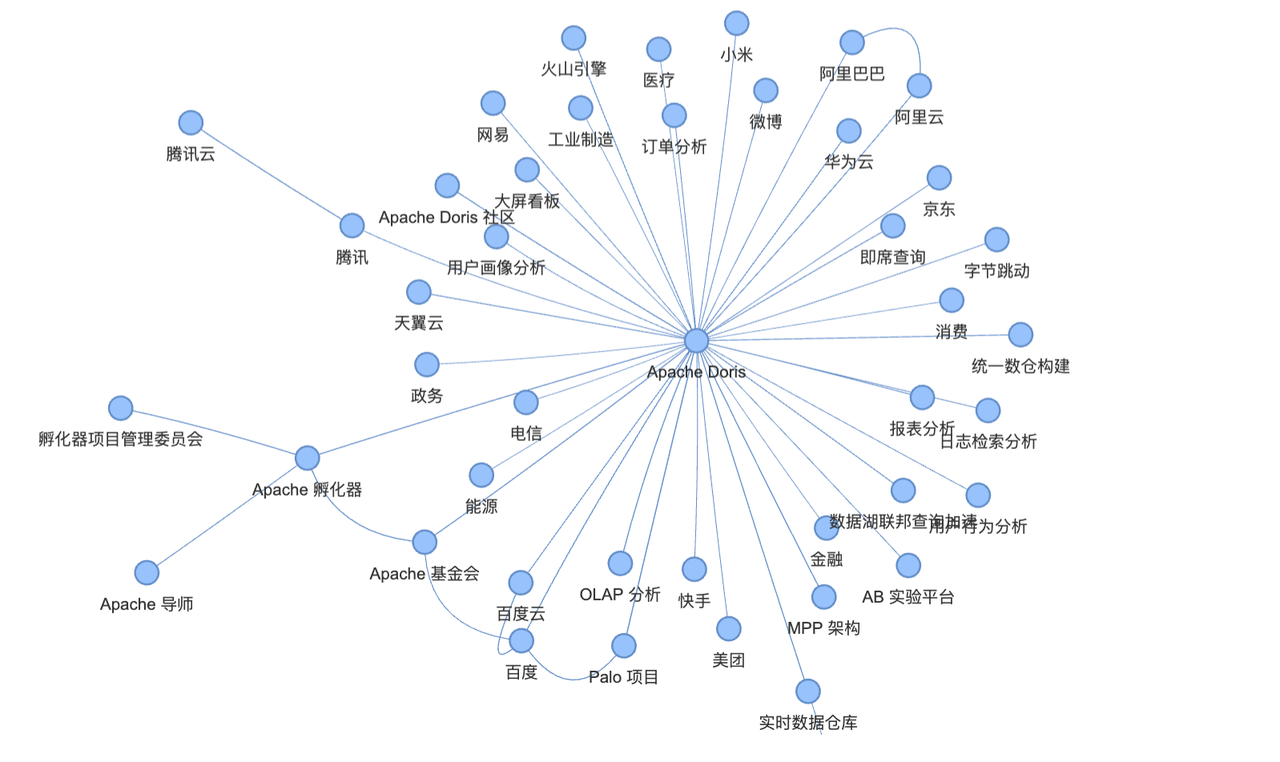
知识图谱的可视化
5.2 知识图谱数据存入 Doris
将构建的知识图谱(实体、关系)生成唯一 ID 和向量嵌入,组装成指定格式后,存入 Doris 的graph_chunk表,实现知识图谱的持久化存储,并支持基于向量的语义检索:
import uuid
import json
# 构造知识图谱数据记录
records = []
# 1. 处理实体
for node, data in G.nodes(data=True):
desc = data.get('description', '')
text_to_embed = f"{node}: {desc}" # 实体嵌入的文本内容
records.append({
"id": str(uuid.uuid4()), "kb_id": "0", "source_id": "0",
"knowledge_graph_kwd": "entity", "entity_kwd": node,
"from_entity_kwd": "", "to_entity_kwd": "",
"content": json.dumps(data), "text_to_embed": text_to_embed
})
# 2. 处理关系
for u, v, data in G.edges(data=True):
desc = data.get('description', '')
text_to_embed = f"{u} -> {v}: {desc}" # 关系嵌入的文本内容
records.append({
"id": str(uuid.uuid4()), "kb_id": "0", "source_id": "0",
"knowledge_graph_kwd": "relation", "entity_kwd": "",
"from_entity_kwd": u, "to_entity_kwd": v,
"content": json.dumps(data), "text_to_embed": text_to_embed
})
# 为实体/关系生成向量嵌入
texts_to_embed = [c["text_to_embed"] for c in records]
embedding_list = embeddings.embed_documents(texts_to_embed)
embed_iter = iter(embedding_list)
for c in records:
c["embedding"] = next(embed_iter)
# 整理导入格式并写入Doris
data_to_insert = [{k: c[k] for k in ["id","kb_id","source_id","knowledge_graph_kwd","entity_kwd","from_entity_kwd","to_entity_kwd","content","embedding"]} for c in records]
graph_table = client.open_table('graph_chunk')
graph_table.add(data_to_insert)
print("知识图谱数据成功存入Doris的graph_chunk表!")
5.3 基于知识图谱的检索与问答
实现实体检索和关系查询两个核心函数,先根据用户查询检索相关实体,再查询实体间的所有关系,构造相关子图,最后基于子图的结构化知识生成答案:
def search_entities(query: str, top_k: int = 100) -> list:
"""向量检索知识图谱中的相关实体"""
query_vec = embeddings.embed_query(query)
graph_table = client.open_table('graph_chunk')
res_df = graph_table.search(query_vec)\
.limit(top_k)\
.where(f"knowledge_graph_kwd = 'entity'")\
.select(["entity_kwd", "content"])\
.to_pandas()
return res_df.to_dict('records')
def get_relations(entity_names: list) -> list:
"""查询实体间的所有关联关系"""
if not entity_names:
return []
placeholders = ','.join(['%s'] * len(entity_names))
sql = f"""
SELECT from_entity_kwd, to_entity_kwd, content
FROM graph_chunk
WHERE knowledge_graph_kwd='relation'
AND (from_entity_kwd IN ({placeholders}) OR to_entity_kwd IN ({placeholders}));
"""
params = entity_names + entity_names
cursor = client.connection.cursor(dictionary=True)
cursor.execute(sql, params)
res = cursor.fetchall()
cursor.close()
return res
# 复杂查询示例:Doris是哪家公司捐赠给Apache基金会,又被哪些公司或组织所使用
query = 'Doris 是哪家公司捐赠给 Apache 基金会,又被哪些公司或组织所使用'
# 步骤1:检索相关实体
entities = search_entities(query)
entity_names = [e['entity_kwd'] for e in entities]
# 步骤2:查询实体间的关系
relations = get_relations(entity_names)
# 步骤3:基于实体关系生成答案
kg_prompt = f"""以下是知识图谱检索到的Doris相关实体关系:{relations}
请根据上述结构化信息,简洁、准确地回答用户问题:{query}"""
kg_resp = llm.invoke(kg_prompt)
print("知识图谱增强RAG答案:\n", kg_resp.content)
5.4 知识图谱增强 RAG 答案示例
捐赠公司
Apache Doris 由百度于 2018 年 7 月捐赠给 Apache 基金会,其最初是百度广告报表业务的 Palo 项目,后开源并交由 Apache 基金会孵化。
主要使用的公司 / 组织
- 互联网公司:中国市值 / 估值前 50 的互联网公司中超 80% 长期使用,包括字节跳动、阿里巴巴、腾讯、美团、小米、京东、网易、快手、微博等;
- 云服务商:阿里云、华为云、天翼云、腾讯云、百度云、火山引擎等,均提供托管的 Apache Doris 云服务并自身使用;
- 传统行业:金融、消费、电信、工业制造、能源、医疗、政务等行业的中大型企业均有广泛应用
6. 结束语
本文基于 Apache Doris 构建了基础 RAG 与知识图谱增强 RAG 两套完整方案,覆盖从文档分片、向量入库到实体关系抽取、图谱构建与检索的核心流程,具备工业级落地能力。相比基础 RAG,知识图谱增强方案能够缓解知识碎片化问题,提升多实体、多关系复杂问题的回答准确性与完整性;而 Apache Doris 则提供了统一的向量检索与结构化 / 非结构化数据存储能力,作为系统的高性能数据底座。
后续扩展方向:
- 查询意图识别:基于大模型识别查询类型(简单问答 / 复杂关系),动态选择基础 RAG 或图谱增强方案;
- 文档增强:引入用户反馈机制,持续优化知识内容,提升检索准确率;
- Agentic RAG:引入智能代理,支持多步检索与推理,提升复杂问题处理能力;
- 增量更新:实现文档与知识图谱的增量更新,保障知识库时效性;
- 索引调优:针对不同规模数据优化 HNSW 参数(如 ef_construction、max_degree),提升检索性能。
读者可基于文中案例进一步探索,让 SelectDB or Apache Doris 成为业务智能化进程中统一、高效的数据基座。
附:相关资源
视频教程
完整代码:https://github.com/freemandealer/apache-doris-rag
官方文档:Apache Doris 官方文档