像 PostgreSQL 和 MySQL 这样的 OLTP(在线事务处理)数据库,凭借其强一致性和高并发事务处理能力,已成为行业标准。为应对更大规模的工作负载,许多团队还会引入分库分表方案,将数据分布到多个实例和表中,以此突破单节点瓶颈。然而,这种对事务行之有效的方案,在实时分析需求(实时运营仪表盘、多维业务报告、用户行为分析和实时监控)面前却暴露出明显短板。
问题的关键不在于将 PostgreSQL 数据库扩展到其设计范围之外的用途,而是在其旁构建一个专用的分析层。本文将介绍如何将 PostgreSQL 与 Apache Doris 结合,构建混合事务/分析处理(HTAP)架构:让 PostgreSQL 专注于事务处理,而 Apache Doris 则负责分析任务——通过实时数据同步、高速聚合和高并发查询能力,为分析场景提供支撑。
为什么 OLTP 数据库不擅长实时分析?
分库分表方案有效解决了事务型数据库的扩展问题。它突破了单节点存储限制,将高并发请求(如秒杀活动、订单高峰)分散到多个节点,在拆分后仍能保证 ACID 特性,并可随业务增长进行水平扩展。但随着分析需求的增加,依赖同一 OLTP 系统来处理事务和分析会暴露出几个根本性的局限性。
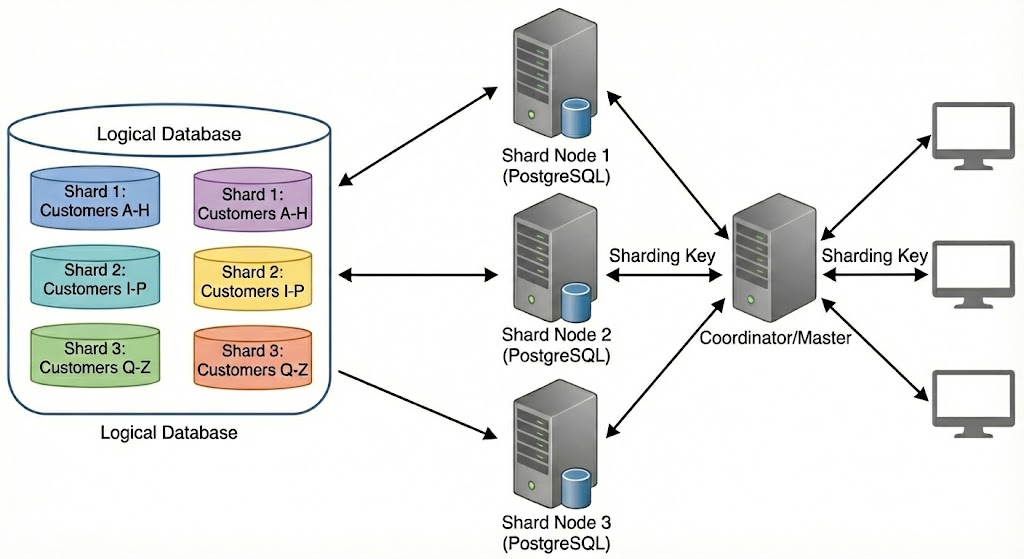
- 分析效率低下:跨分库、跨分表的关联查询(如多表 Join、多维度聚合)需手动拼接分片数据,SQL 编写复杂且存在大量跨节点数据传输,导致查询延迟高、资源消耗大;
- 成本高昂:TP(事务处理)系统的设计核心是适配在线高并发事务场景,其存储架构更侧重性能优化而非成本控制,若用于存储海量历史数据,会导致存储成本显著增加;
- 隔离性缺失:数据分析通常伴随大量计算与存储资源占用,若与在线 TP(事务处理)系统共享资源,易引发资源竞争,进而影响交易业务的响应速度与系统稳定性。
- 存储冗余与 I/O 激增: PostgreSQL 的 MVCC(多版本并发控制)机制采用“仅追加”(Append-Only)存储模式。这意味着每次更新操作都会在磁盘上复制整行数据,导致大量的无效死元组(Dead Tuples)积累,形成表膨胀(Table Bloat)。对于分析查询而言,必须扫描这些冗余数据,造成查询 I/O 成本激增和性能显著衰退,极大地增加了存储和计算资源的消耗。
- 垃圾回收效率低下与运维复杂: PostgreSQL 依赖复杂的 Autovacuum 机制来清理死元组。然而,这一机制难以调优,且易被分析场景中常见的长事务阻塞,进一步加剧了表膨胀的恶性循环。更糟糕的是,常规的 VACUUM 无法回收磁盘空间,必须运行资源消耗巨大且耗时的 VACUUM FULL 操作,严重影响生产环境的连续可用性。
- 高并发分析与连接瓶颈: PostgreSQL 采用的进程-连接(Process-per-Connection)模型在应对分析场景下的高并发连接时,性能衰减迅速,难以实现大规模并发查询的线性扩展。
HTAP 架构:PostgreSQL + Apache Doris
Apache Doris 是基于 MPP(大规模并行处理)架构构建的高性能实时分析型数据库。它专为高速复杂查询、实时数据更新、高并发工作负载而设计,常用于实时报表和分析、实时监控、用户画像等场景。Doris 还能与主流数据同步工具无缝集成。
SelectDB 作为 Apache Doris 的核心贡献者和商业化团队,在 Doris 开源内核基础上,提供了企业级特性、全托管运维服务及专业技术支持,帮助企业更便捷地将 Doris 能力应用于生产环境。
这种 HTAP 架构的核心思想很简单:将事务与分析业务在物理上实现分离。PostgreSQL 处理在线事务处理,Apache Doris 处理分析任务。数据通过 Kafka、Flink CDC、DataX 或 Apache SeaTunnel 等同步工具从 PostgreSQL 流向 Apache Doris,在不影响事务系统的情况下保持分析层的最新状态。
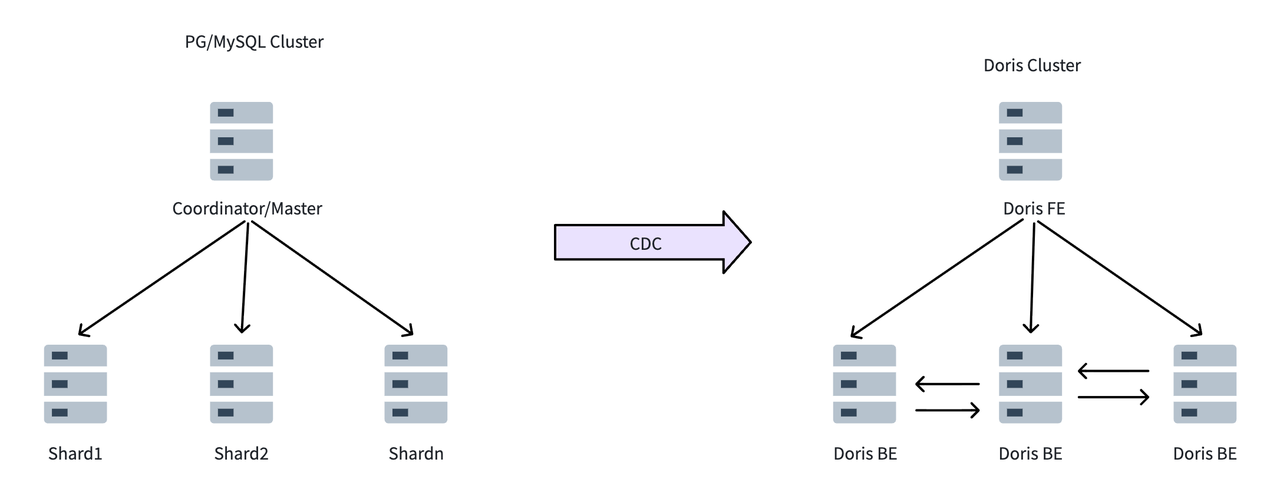
数据同步策略
数据同步是保障分析数据准确性与实时性的核心环节,需根据业务场景选择合适的同步工具与策略:
- 全量同步:适用于初始化场景,通过 DataX、Sqoop 等工具,读取 MySQL/PostgreSQL 分库分表的全量数据,按 Doris 表结构进行格式转换后批量写入,完成初始数据对齐;
- 增量同步:针对交易数据的实时变动,采用 Flink CDC(Change Data Capture)工具,捕获分库分表中的 INSERT、UPDATE、DELETE 操作日志,实时传输至 Doris。Flink CDC 支持断点续传、数据去重,确保增量数据的完整性与一致性;
- 同步频率控制:对于高频变动数据(如订单状态),采用实时同步(延迟≤10 秒);对于低频变动数据(如用户基础信息),采用定时增量同步(如 5 分钟一次),平衡实时性与资源消耗。
Doris 表结构设计
为适配分库分表数据与分析需求,Doris 表结构设计需遵循以下原则:
- 分区设计:按时间维度(如天分区)或业务维度(如区域、业务线)进行分区,减少查询时的数据扫描范围,提升查询效率;
- 分桶设计:针对大表,按高频查询字段(如用户 ID、订单 ID)进行分桶,使数据均匀分布在 Doris 各个节点,充分发挥 MPP 并行计算能力;
- 表引擎选择:核心业务表采用 Mow(Merge-on-Write)表引擎,支持行级近实时更新;离线分析表采用 Aggregate 表引擎,通过预聚合提升聚合查询效率。
核心优势
实时数据更新
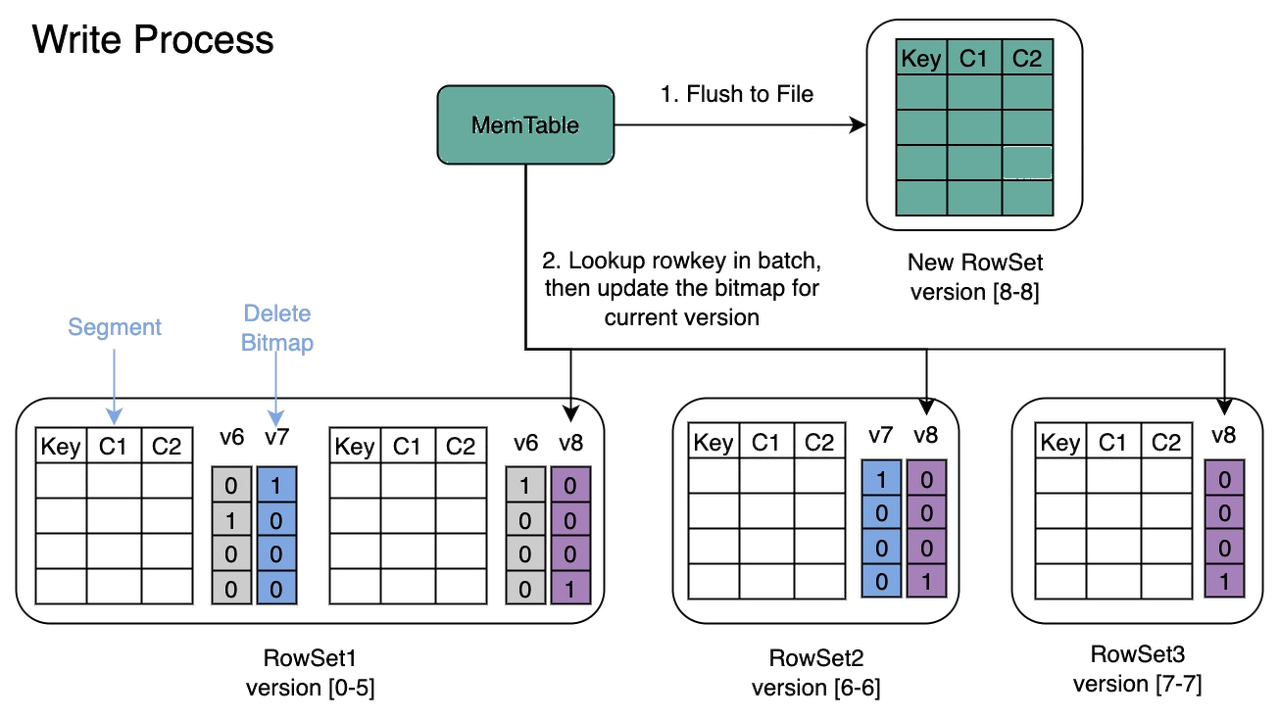
Apache Doris 的 Merge-On-Write(MOW)引擎专为实时更新场景设计。无需依赖后台大量异步 Compaction,MOW 在数据写入阶段即完成合并,更新后的数据可秒级可见,完美适配高频小批量更新、实时数据同步等场景(如订单状态实时变更)。
MOW 支持全范围的 DML 操作(INSERT、DELETE、UPDATE、UPSERT),并能与 CDC 工具和其他数据导入工具无缝协作,适配 PostgreSQL/MySQL 等数据源的实时同步需求,现有查询 SQL 与核心功能(向量引擎、物化视图、分区 TTL 等)可直接复用,无额外适配成本。
高速分析查询
大多数数据库基准测试基于静态数据集。但在生产环境中,数据高频更新下进行性能测试,才能展现真实的生产适配能力。
以 Star Schema Benchmark(SSB)SF100 数据集为基准,在 25%的数据持续更新的情况下,Apache Doris 的整体性能比 ClickHouse 快 25 倍,显著凸显其在实时更新场景下的优势。
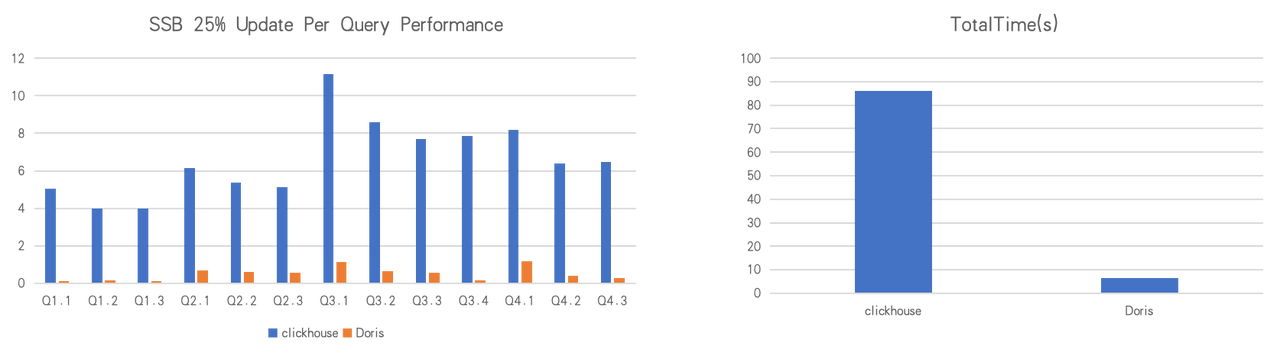
注: Apache Doris 与 ClickHouse 在实时更新方面的比较
Apache Doris 的性能优势来自两个方面:
- 执行引擎。Apache Doris 采用向量化执行引擎,以批量方式处理数据,从而降低每条指令的开销。其基于成本的优化器(CBO)会分析数据统计信息,自动选择最优查询计划,包括 Join 顺序、扫描方式和聚合策略,从而将复杂查询的执行成本降至最低。
- 存储结构。MOW 引擎在写入时对数据进行排序、编码和合并,生成规范的、组织良好的存储结构。在查询时,无需扫描分散的增量日志,也无需进行即时合并计算。这种“写时合并、读时轻量”的设计方法使查询延迟保持稳定且可预测,这对于实时仪表盘和 SLA 约束报告等对延迟敏感的用例至关重要。
工作负载隔离
将分析型业务(AP)迁移到 Apache Doris 后,事务(TP)与分析(AP)在物理独立的集群上运行,彻底消除资源争用:分析查询不再挤占生产事务的 CPU 和内存,也不再出现因报表误时运行而导致事务超时的风险。
PostgreSQL 始终专注于其最擅长的事务处理。Apache Doris 则独立承担所有分析性的繁重任务。每个系统都有自己的资源,且互不干扰。
降低存储成本
Apache Doris 提供存算分离与存算一体两种部署模式下的分层存储方案,可灵活适配不同业务场景,实现性能与成本的平衡。
- 存算分离架构:采用“本地缓存 + 远端对象存储”的分层策略。热数据(高频访问、对延迟敏感)缓存在计算节点本地磁盘,确保低延迟查询响应;冷数据(低频访问、体量大)则自动沉降到兼容 S3 的对象存储(如 AWS S3、阿里云 OSS),在突破本地存储限制的同时,显著降低长期存储成本。
- 存算一体架构:支持按数据访问热度进行多介质存储适配。热数据部署于 SSD,充分发挥高 IOPS 与低延迟优势,保障高并发与复杂分析的性能;冷数据则迁移至成本更低的 HDD,通过“热 SSD + 冷 HDD”的组合,在满足业务性能需求的前提下,有效控制硬件采购与运维成本。
两种模式均基于访问模式使用智能数据分层,实现同一目标:热数据高性能,冷数据低成本。为海量数据下的存储与分析提供了灵活、经济的优化路径。
客户使用收益
森马:400% QPS 提升(MySQL )
森马服饰作为中国休闲服饰和童装领域的领先企业,覆盖线上线下全渠道零售,门店总数达到 8000+ 家。为支持其全渠道库存管理平台,森马将其 Elasticsearch +分布式 MySQL 架构替换为阿里云 S****electDB 版(由 Apache Doris 提供支持的云服务),统一了 16 条以上核心业务线的分析,复杂查询 QPS 提升 400%,响应时间缩短至秒级。
- 多场景并发支撑:同时支撑 2B 业务、2C 业务、直营店、加盟商等多场景下的高并发数据分析需求,复杂查询的 QPS 提升 400%,达到 200+ QPS
- 资源隔离:使用独立的计算组实现在线订单查询与批量 BI 分析之间的资源隔离,避免相互干扰,确保高并发场景下系统稳定性。
- 弹性扩缩容:在重要的直播销售活动期间,无需停机或数据迁移,可快速在线扩容应对流量激增。
- 统一架构:简化架构取代双系统设置,在一个系统中支持从简单过滤器到复杂多表连接的所有功能
阿里云数据库 SelectDB 版作为阿里云原生服务,与 VPC、RAM 权限、监控等云服务无缝集成,提供类似在用户 VPC 内部署的网络体验,让用户享受更便捷的云端管理能力。
完整阅读:森马服饰从 Elasticsearch 到阿里云 SelectDB 的架构演进之路
天眼查:查询延迟降低 70%(PostgreSQL)
天眼查是一家亚洲的企业数据服务公司,提供超过 3 亿家公司的商业、金融和法律信息,涵盖 300 多个数据维度。天眼查将其混合架构的 Apache Hive、MySQL、PostgreSQL 和 Elasticsearch 替换为 Apache Doris,2 个 Apache Doris 集群承载数十 TB 数据,实现数据写入效率提升 75%,用户分群延迟降低 70%。
- 即席查询能力:此前,每一个新的分析请求都需要在 Hive 中构建和测试数据模型,然后在 MySQL 中调度作业。现在,由于所有详细数据都存储在 Apache Doris 中,新请求只需配置查询条件即可运行即席查询,无需进行定制开发。
- 高效用户分群:对于结果集在 500 万以下的细分任务,Apache Doris 可实现毫秒级响应。通过优化连续用户 ID 映射,细分延迟降低了 70%。
- 统一架构:消除了多组件间的复杂读写操作,无需预定义用户标签,标签可基于任务条件自动生成,大幅简化用户分群流程,提高 A/B 测试的灵活性。
- 稳定数据写入:针对不同场景使用不同的数据模型:MySQL 数据采用 Unique 模型,日志数据采用 Duplicate 模型,DWS 层数据采用 Aggregate 模型,每天支持近 10 亿条新记录的处理。
完整阅读:秒级数据写入,毫秒查询响应,天眼查基于 Apache Doris 构建统一实时数仓
结束语
PostgreSQL 和 MySQL 搭配分库分表,仍然是高并发事务处理的可靠选择。但其面对现代企业面临的实时分析需求仍存在天然局限。这种 HTAP 架构将 OLTP 系统与 Apache Doris 组合,在基础设施层面将事务与分析分离:每个系统都能发挥其所长,且不会对另一个系统造成影响。其结果是分析查询速度更快、事务性能稳定,且存储成本更低。如果您正在 PostgreSQL 或 MySQL 集群上运行分析工作负载,并感到压力,那么这种架构值得探索。
若想了解更多关于 Apache Doris 的信息,请加入社区交流群。如果您正在寻找完全托管的 Apache Doris 云服务,可从下方链接试用或直接联系 SelectDB 团队。
- 想立即体验?SelectDB Cloud 免费试用
- 需要私有化部署?SelectDB Enterprise 下载试用
- 已是阿里云用户?阿里云数据库 SelectDB 版 一键启用




